 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAleatoric and Epistemic Discrimination in Classification
Paper and Code
Jan 27, 2023
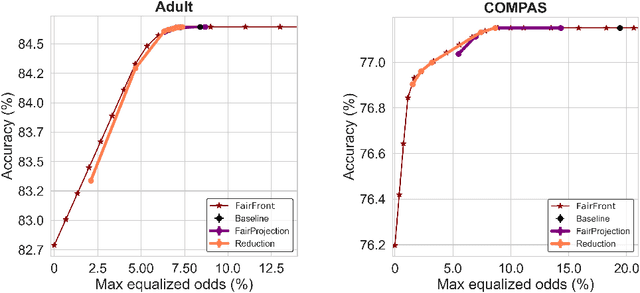
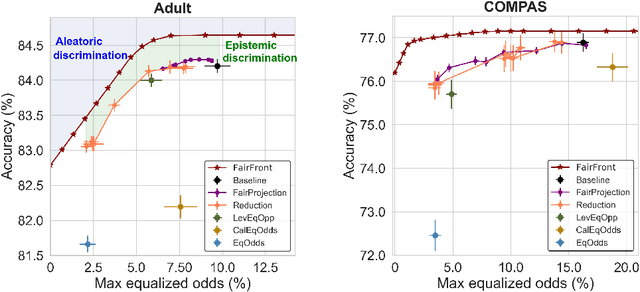

Machine learning (ML) models can underperform on certain population groups due to choices made during model development and bias inherent in the data. We categorize sources of discrimination in the ML pipeline into two classes: aleatoric discrimination, which is inherent in the data distribution, and epistemic discrimination, which is due to decisions during model development. We quantify aleatoric discrimination by determining the performance limits of a model under fairness constraints, assuming perfect knowledge of the data distribution. We demonstrate how to characterize aleatoric discrimination by applying Blackwell's results on comparing statistical experiments. We then quantify epistemic discrimination as the gap between a model's accuracy given fairness constraints and the limit posed by aleatoric discrimination. We apply this approach to benchmark existing interventions and investigate fairness risks in data with missing values. Our results indicate that state-of-the-art fairness interventions are effective at removing epistemic discrimination. However, when data has missing values, there is still significant room for improvement in handling aleatoric discrimination.