 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAES Systems Are Both Overstable And Oversensitive: Explaining Why And Proposing Defenses
Paper and Code


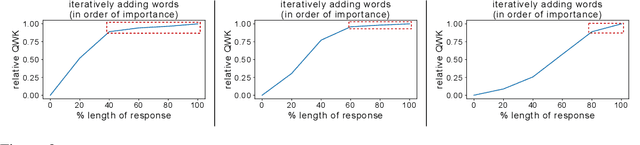

Deep-learning based Automatic Essay Scoring (AES) systems are being actively used by states and language testing agencies alike to evaluate millions of candidates for life-changing decisions ranging from college applications to visa approvals. However, little research has been put to understand and interpret the black-box nature of deep-learning based scoring algorithms. Previous studies indicate that scoring models can be easily fooled. In this paper, we explore the reason behind their surprising adversarial brittleness. We utilize recent advances in interpretability to find the extent to which features such as coherence, content, vocabulary, and relevance are important for automated scoring mechanisms. We use this to investigate the oversensitivity i.e., large change in output score with a little change in input essay content) and overstability i.e., little change in output scores with large changes in input essay content) of AES. Our results indicate that autoscoring models, despite getting trained as "end-to-end" models with rich contextual embeddings such as BERT, behave like bag-of-words models. A few words determine the essay score without the requirement of any context making the model largely overstable. This is in stark contrast to recent probing studies on pre-trained representation learning models, which show that rich linguistic features such as parts-of-speech and morphology are encoded by them. Further, we also find that the models have learnt dataset biases, making them oversensitive. To deal with these issues, we propose detection-based protection models that can detect oversensitivity and overstability causing samples with high accuracies. We find that our proposed models are able to detect unusual attribution patterns and flag adversarial samples successfully.