 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdversarial Speaker-Consistency Learning Using Untranscribed Speech Data for Zero-Shot Multi-Speaker Text-to-Speech
Paper and Code
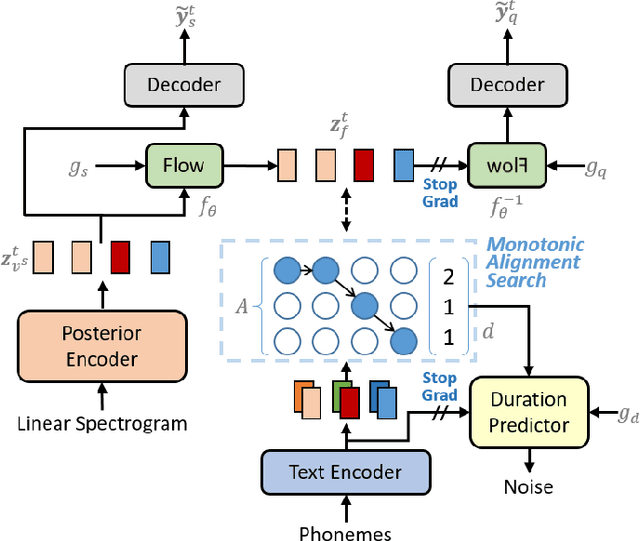
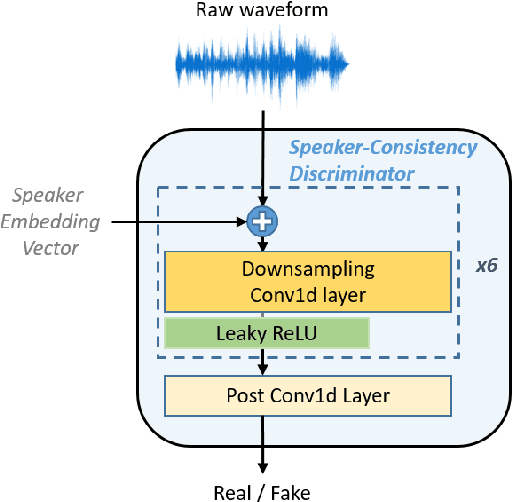

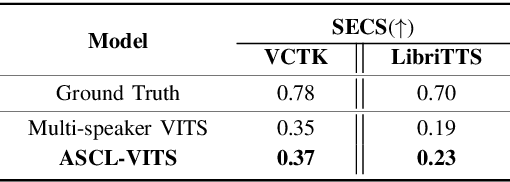
Several recently proposed text-to-speech (TTS) models achieved to generate the speech samples with the human-level quality in the single-speaker and multi-speaker TTS scenarios with a set of pre-defined speakers. However, synthesizing a new speaker's voice with a single reference audio, commonly known as zero-shot multi-speaker text-to-speech (ZSM-TTS), is still a very challenging task. The main challenge of ZSM-TTS is the speaker domain shift problem upon the speech generation of a new speaker. To mitigate this problem, we propose adversarial speaker-consistency learning (ASCL). The proposed method first generates an additional speech of a query speaker using the external untranscribed datasets at each training iteration. Then, the model learns to consistently generate the speech sample of the same speaker as the corresponding speaker embedding vector by employing an adversarial learning scheme. The experimental results show that the proposed method is effective compared to the baseline in terms of the quality and speaker similarity in ZSM-TTS.