 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdversarial Multimodal Representation Learning for Click-Through Rate Prediction
Paper and Code
Mar 07, 2020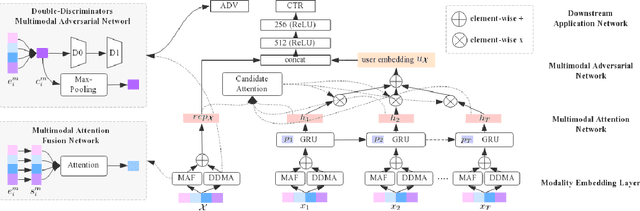

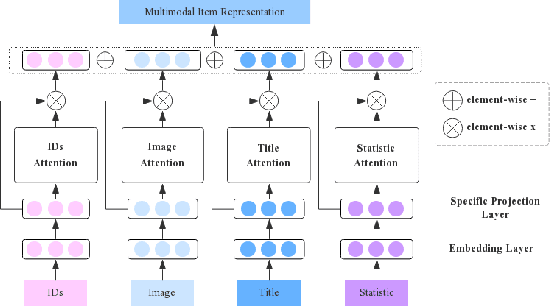
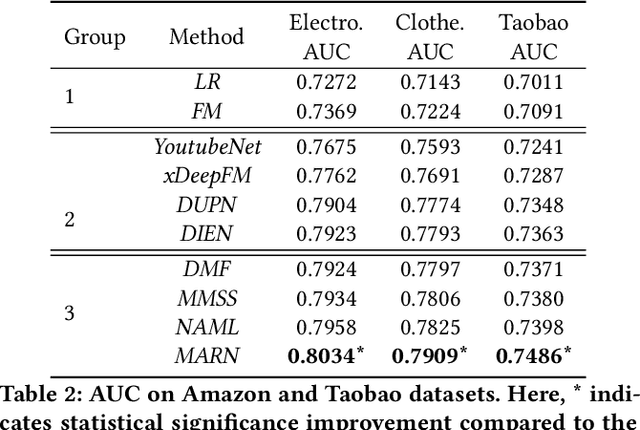
For better user experience and business effectiveness, Click-Through Rate (CTR) prediction has been one of the most important tasks in E-commerce. Although extensive CTR prediction models have been proposed, learning good representation of items from multimodal features is still less investigated, considering an item in E-commerce usually contains multiple heterogeneous modalities. Previous works either concatenate the multiple modality features, that is equivalent to giving a fixed importance weight to each modality; or learn dynamic weights of different modalities for different items through technique like attention mechanism. However, a problem is that there usually exists common redundant information across multiple modalities. The dynamic weights of different modalities computed by using the redundant information may not correctly reflect the different importance of each modality. To address this, we explore the complementarity and redundancy of modalities by considering modality-specific and modality-invariant features differently. We propose a novel Multimodal Adversarial Representation Network (MARN) for the CTR prediction task. A multimodal attention network first calculates the weights of multiple modalities for each item according to its modality-specific features. Then a multimodal adversarial network learns modality-invariant representations where a double-discriminators strategy is introduced. Finally, we achieve the multimodal item representations by combining both modality-specific and modality-invariant representations. We conduct extensive experiments on both public and industrial datasets, and the proposed method consistently achieves remarkable improvements to the state-of-the-art methods. Moreover, the approach has been deployed in an operational E-commerce system and online A/B testing further demonstrates the effectiveness.