 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdversarial Joint Training with Self-Attention Mechanism for Robust End-to-End Speech Recognition
Paper and Code
Apr 03, 2021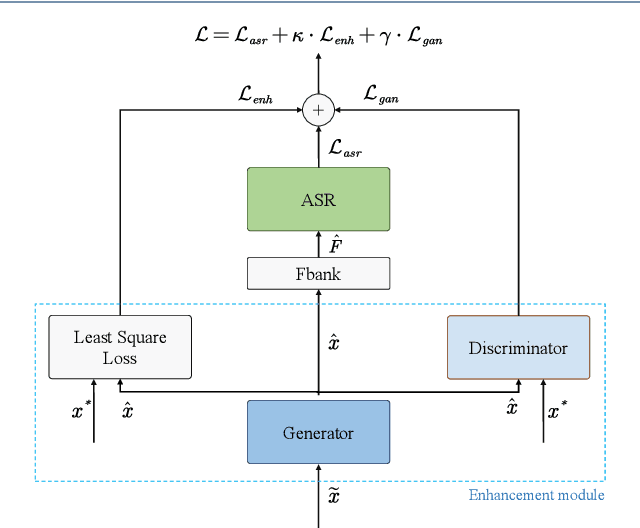

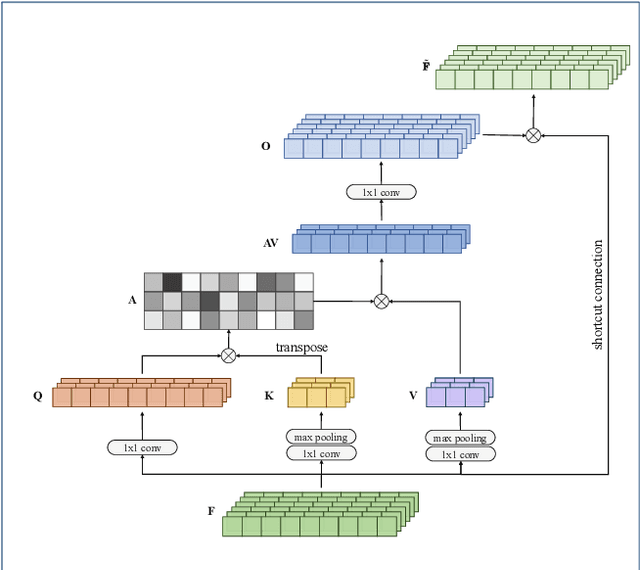
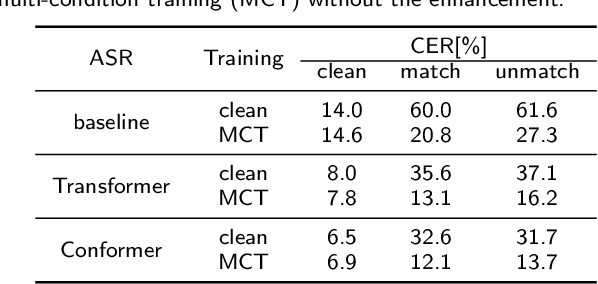
Lately, the self-attention mechanism has marked a new milestone in the field of automatic speech recognition (ASR). Nevertheless, its performance is susceptible to environmental intrusions as the system predicts the next output symbol depending on the full input sequence and the previous predictions. Inspired by the extensive applications of the generative adversarial networks (GANs) in speech enhancement and ASR tasks, we propose an adversarial joint training framework with the self-attention mechanism to boost the noise robustness of the ASR system. Generally, it consists of a self-attention speech enhancement GAN and a self-attention end-to-end ASR model. There are two highlights which are worth noting in this proposed framework. One is that it benefits from the advancement of both self-attention mechanism and GANs; while the other is that the discriminator of GAN plays the role of the global discriminant network in the stage of the adversarial joint training, which guides the enhancement front-end to capture more compatible structures for the subsequent ASR module and thereby offsets the limitation of the separate training and handcrafted loss functions. With the adversarial joint optimization, the proposed framework is expected to learn more robust representations suitable for the ASR task. We execute systematic experiments on the corpus AISHELL-1, and the experimental results show that on the artificial noisy test set, the proposed framework achieves the relative improvements of 66% compared to the ASR model trained by clean data solely, 35.1% compared to the speech enhancement & ASR scheme without joint training, and 5.3% compared to multi-condition training.