 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdversarial Example Detection in Deployed Tree Ensembles
Paper and Code
Jun 27, 2022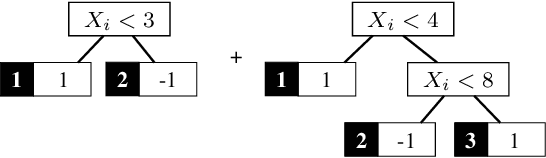
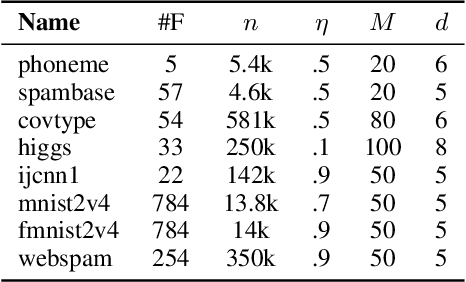
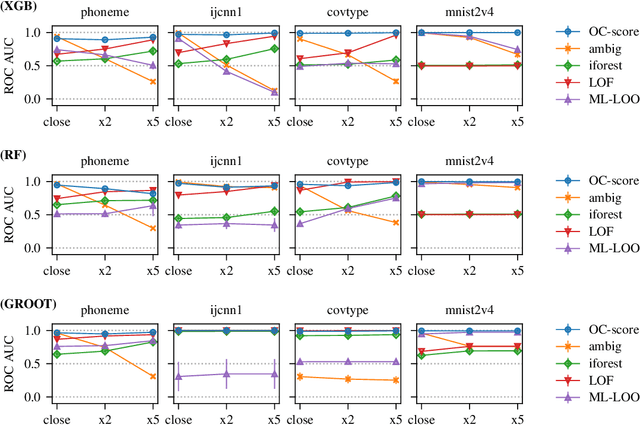
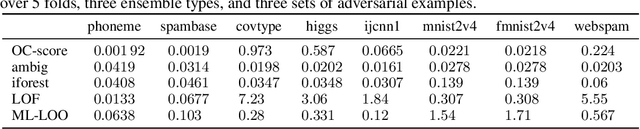
Tree ensembles are powerful models that are widely used. However, they are susceptible to adversarial examples, which are examples that purposely constructed to elicit a misprediction from the model. This can degrade performance and erode a user's trust in the model. Typically, approaches try to alleviate this problem by verifying how robust a learned ensemble is or robustifying the learning process. We take an alternative approach and attempt to detect adversarial examples in a post-deployment setting. We present a novel method for this task that works by analyzing an unseen example's output configuration, which is the set of predictions made by an ensemble's constituent trees. Our approach works with any additive tree ensemble and does not require training a separate model. We evaluate our approach on three different tree ensemble learners. We empirically show that our method is currently the best adversarial detection method for tree ensembles.