 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdversarial Attacks Against Medical Deep Learning Systems
Paper and Code
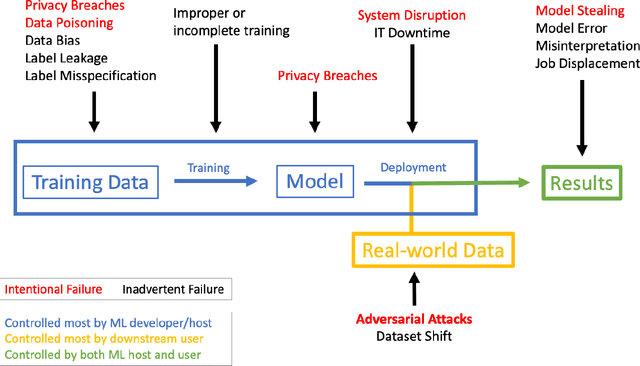
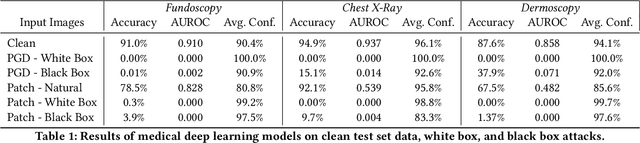
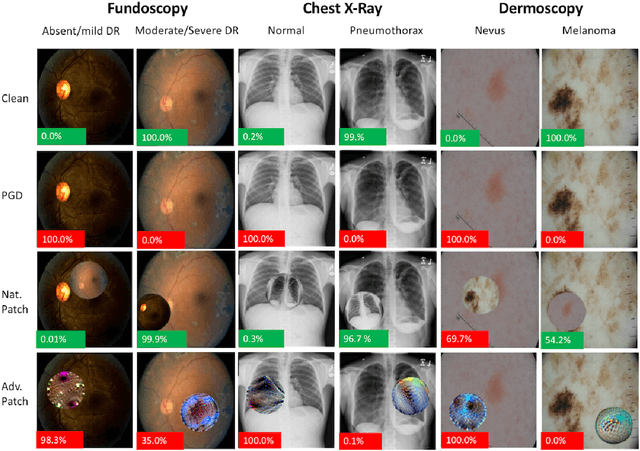
The discovery of adversarial examples has raised concerns about the practical deployment of deep learning systems. In this paper, we argue that the field of medicine may be uniquely susceptible to adversarial attacks, both in terms of monetary incentives and technical vulnerability. To this end, we outline the healthcare economy and the incentives it creates for fraud, we extend adversarial attacks to three popular medical imaging tasks, and we provide concrete examples of how and why such attacks could be realistically carried out. For each of our representative medical deep learning classifiers, both white and black box attacks were highly successful. We urge caution in deploying deep learning systems in clinical settings, and encourage the machine learning community to further investigate the domain-specific characteristics of medical learning systems.