Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaTask: Adaptive Multitask Online Learning
Paper and Code
May 31, 2022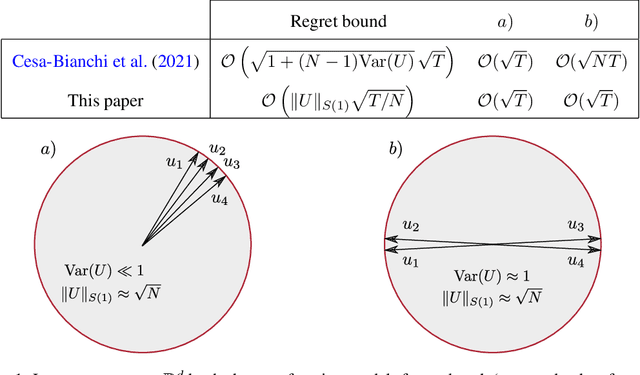
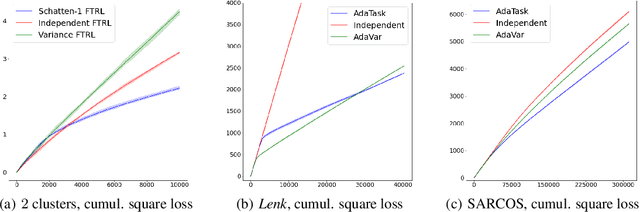
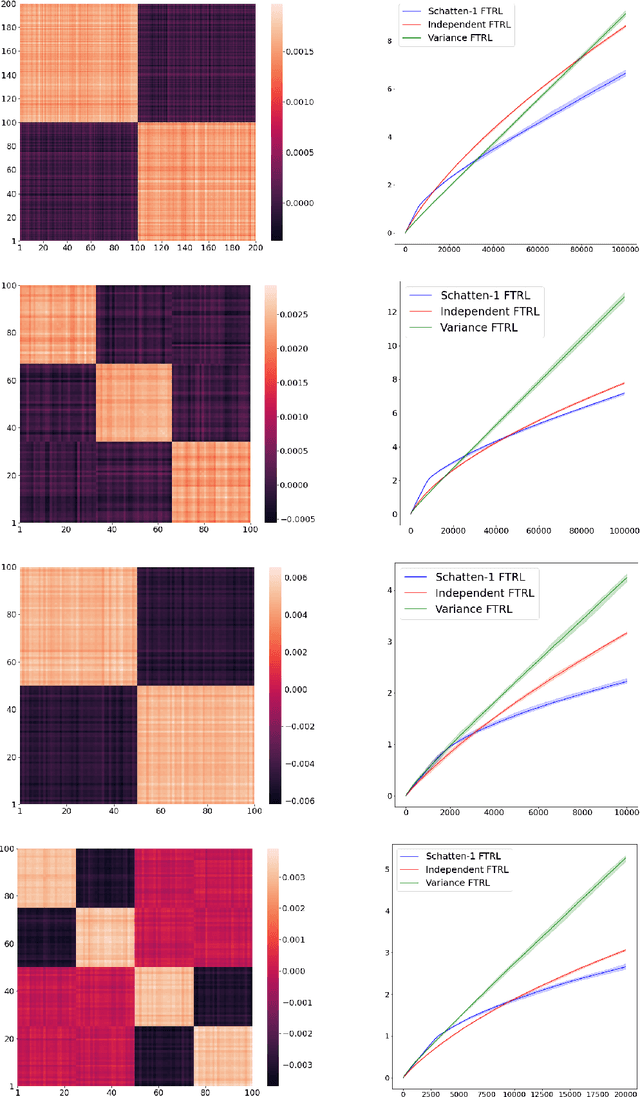
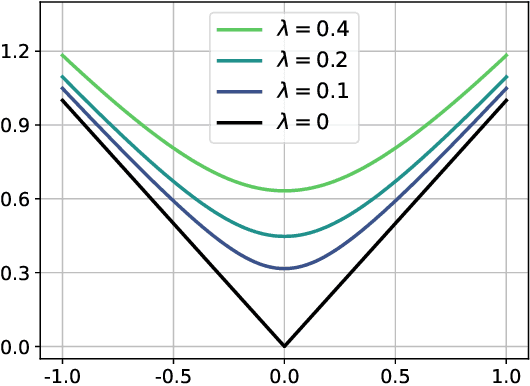
We introduce and analyze AdaTask, a multitask online learning algorithm that adapts to the unknown structure of the tasks. When the $N$ tasks are stochastically activated, we show that the regret of AdaTask is better, by a factor that can be as large as $\sqrt{N}$, than the regret achieved by running $N$ independent algorithms, one for each task. AdaTask can be seen as a comparator-adaptive version of Follow-the-Regularized-Leader with a Mahalanobis norm potential. Through a variational formulation of this potential, our analysis reveals how AdaTask jointly learns the tasks and their structure. Experiments supporting our findings are presented.
View paper on