 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeADASS: Adaptive Sample Selection for Training Acceleration
Paper and Code
Jun 11, 2019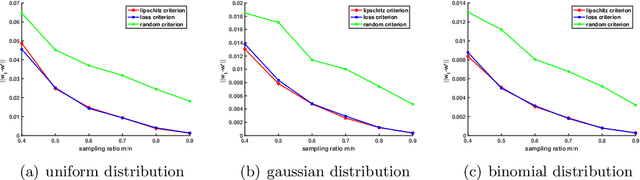
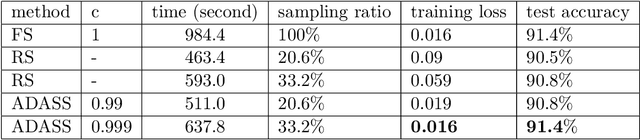
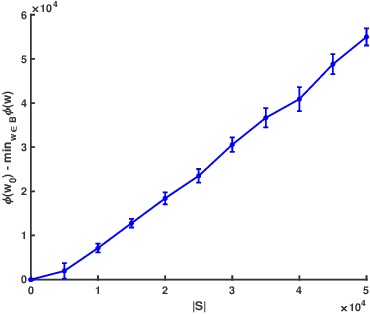
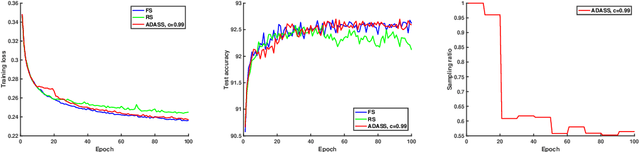
Stochastic gradient decent~(SGD) and its variants, including some accelerated variants, have become popular for training in machine learning. However, in all existing SGD and its variants, the sample size in each iteration~(epoch) of training is the same as the size of the full training set. In this paper, we propose a new method, called \underline{ada}ptive \underline{s}ample \underline{s}election~(ADASS), for training acceleration. During different epoches of training, ADASS only need to visit different training subsets which are adaptively selected from the full training set according to the Lipschitz constants of the loss functions on samples. It means that in ADASS the sample size in each epoch of training can be smaller than the size of the full training set, by discarding some samples. ADASS can be seamlessly integrated with existing optimization methods, such as SGD and momentum SGD, for training acceleration. Theoretical results show that the learning accuracy of ADASS is comparable to that of counterparts with full training set. Furthermore, empirical results on both shallow models and deep models also show that ADASS can accelerate the training process of existing methods without sacrificing accuracy.