 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptive Tag Selection for Image Annotation
Paper and Code
Sep 17, 2014

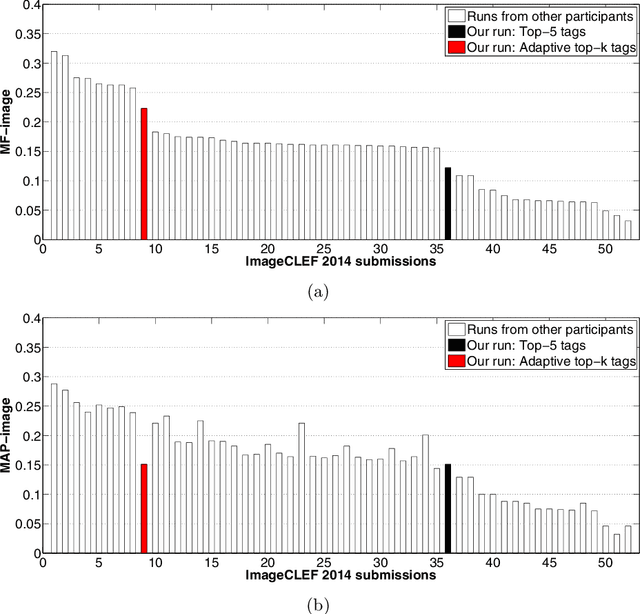

Not all tags are relevant to an image, and the number of relevant tags is image-dependent. Although many methods have been proposed for image auto-annotation, the question of how to determine the number of tags to be selected per image remains open. The main challenge is that for a large tag vocabulary, there is often a lack of ground truth data for acquiring optimal cutoff thresholds per tag. In contrast to previous works that pre-specify the number of tags to be selected, we propose in this paper adaptive tag selection. The key insight is to divide the vocabulary into two disjoint subsets, namely a seen set consisting of tags having ground truth available for optimizing their thresholds and a novel set consisting of tags without any ground truth. Such a division allows us to estimate how many tags shall be selected from the novel set according to the tags that have been selected from the seen set. The effectiveness of the proposed method is justified by our participation in the ImageCLEF 2014 image annotation task. On a set of 2,065 test images with ground truth available for 207 tags, the benchmark evaluation shows that compared to the popular top-$k$ strategy which obtains an F-score of 0.122, adaptive tag selection achieves a higher F-score of 0.223. Moreover, by treating the underlying image annotation system as a black box, the new method can be used as an easy plug-in to boost the performance of existing systems.