 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptive Sampling for Convex Regression
Paper and Code
Aug 26, 2018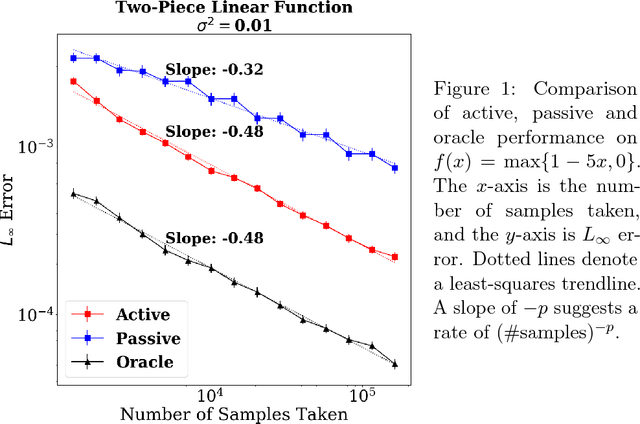
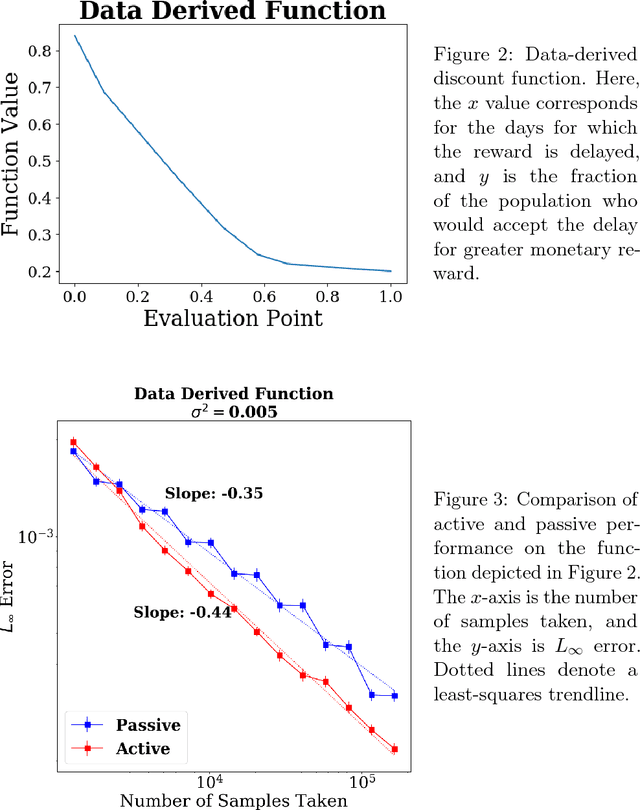

In this paper, we introduce the first principled adaptive-sampling procedure for learning a convex function in the $L_\infty$ norm, a problem that arises often in the behavioral and social sciences. We present a function-specific measure of complexity and use it to prove that, for each convex function $f_{\star}$, our algorithm nearly attains the information-theoretically optimal, function-specific error rate. We also corroborate our theoretical contributions with numerical experiments, finding that our method substantially outperforms passive, uniform sampling for favorable synthetic and data-derived functions in low-noise settings with large sampling budgets. Our results also suggest an idealized "oracle strategy", which we use to gauge the potential advance of any adaptive-sampling strategy over passive sampling, for any given convex function.