Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptive joint distribution learning
Paper and Code
Oct 10, 2021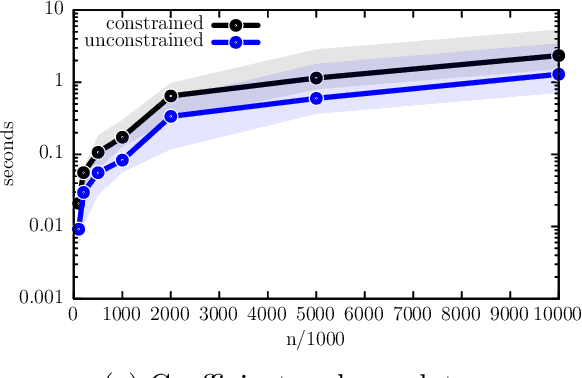
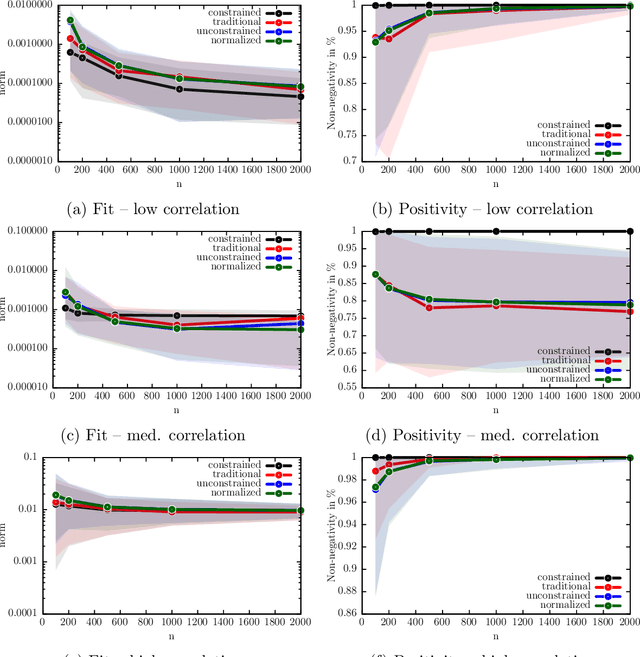
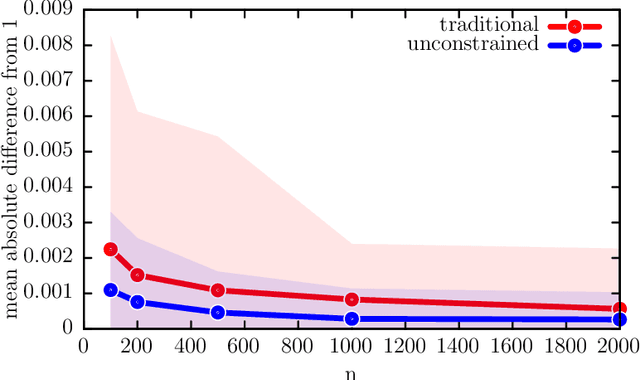
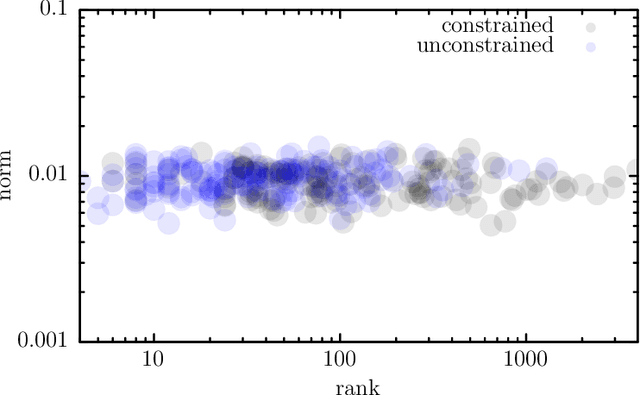
We develop a new framework for embedding (joint) probability distributions in tensor product reproducing kernel Hilbert spaces (RKHS). This framework accommodates a low-dimensional, positive, and normalized model of a Radon-Nikodym derivative, estimated from sample sizes of up to several million data points, alleviating the inherent limitations of RKHS modeling. Well-defined normalized and positive conditional distributions are natural by-products to our approach. The embedding is fast to compute and naturally accommodates learning problems ranging from prediction to classification. The theoretical findings are supplemented by favorable numerical results.
View paper on