 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptive Graph Representation Learning for Video Person Re-identification
Paper and Code
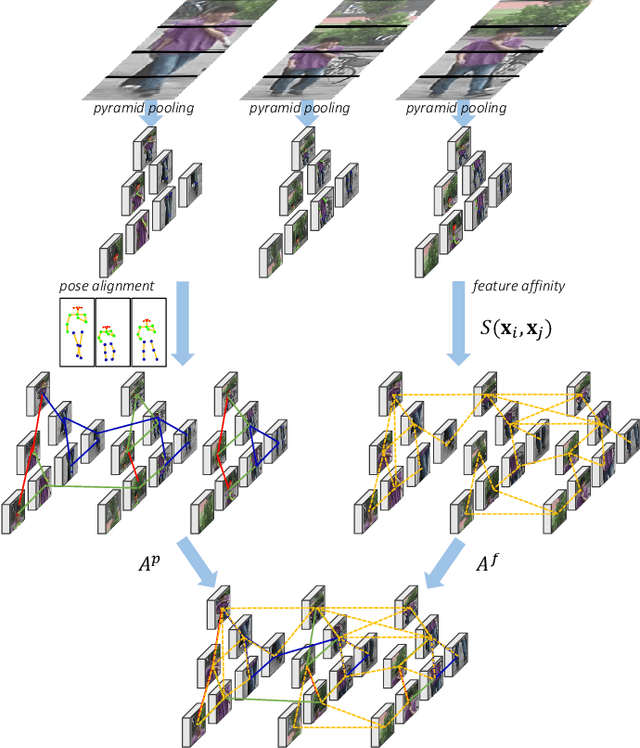

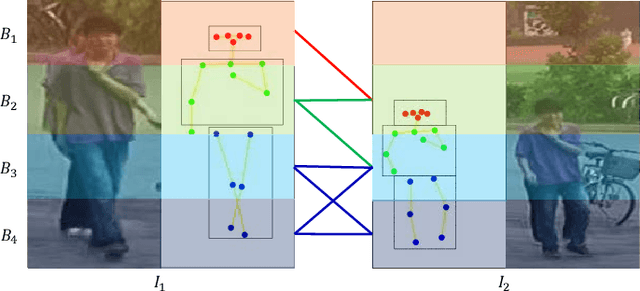
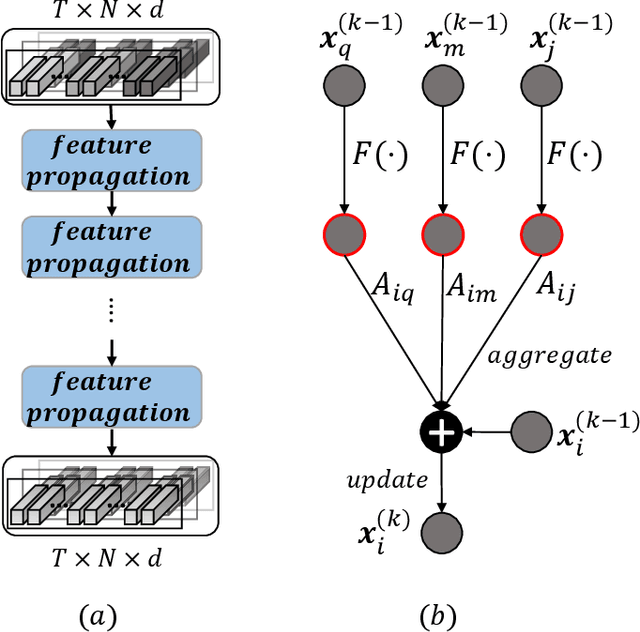
Recent years have witnessed a great development of deep learning based video person re-identification (Re-ID). A key factor for video person Re-ID is how to effectively construct discriminative video feature representations for the robustness to many complicated situations like occlusions. Recent part-based approaches employ spatial and temporal attention to extract the representative local features. While the correlations between the parts are ignored in the previous methods, to leverage the relations of different parts, we propose an innovative adaptive graph representation learning scheme for video person Re-ID, which enables the contextual interactions between the relevant regional features. Specifically, we exploit pose alignment connection and feature affinity connection to construct an adaptive structure-aware adjacency graph, which models the intrinsic relations between graph nodes. We perform feature propagation on the adjacency graph to refine the original regional features iteratively, the neighbor nodes information is taken into account for part feature representation. To learn the compact and discriminative representations, we further propose a novel temporal resolution-aware regularization, which enforces the consistency among different temporal resolutions for the same identities. We conduct extensive evaluations on four benchmarks, i.e. iLIDS-VID, PRID2011, MARS, and DukeMTMC-VideoReID, the experimental results achieve the competitive performance which demonstrates the effectiveness of our proposed method.