Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptive Estimator Selection for Off-Policy Evaluation
Paper and Code
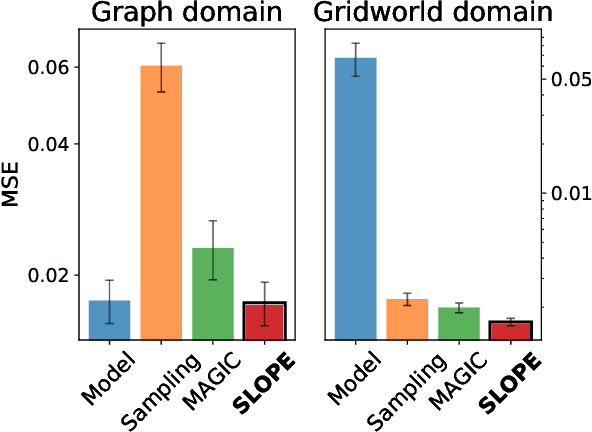

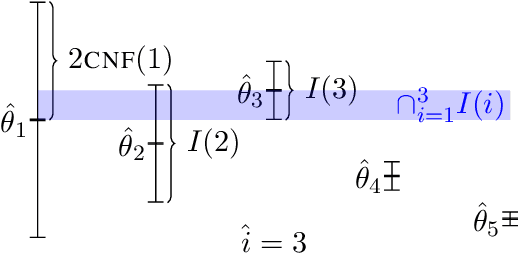
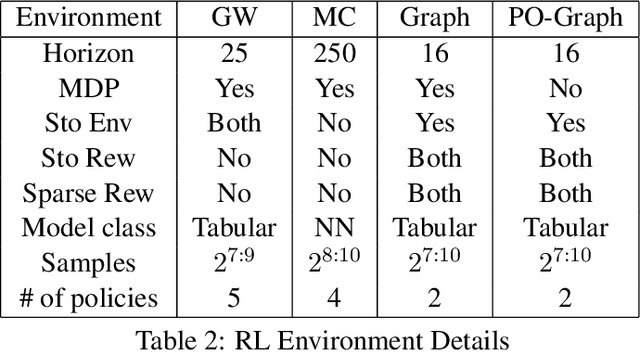
We develop a generic data-driven method for estimator selection in off-policy policy evaluation settings. We establish a strong performance guarantee for the method, showing that it is competitive with the oracle estimator, up to a constant factor. Via in-depth case studies in contextual bandits and reinforcement learning, we demonstrate the generality and applicability of the method. We also perform comprehensive experiments, demonstrating the empirical efficacy of our approach and comparing with related approaches. In both case studies, our method compares favorably with existing methods.
View paper on