 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaFocus: Towards End-to-end Weakly Supervised Learning for Long-Video Action Understanding
Paper and Code
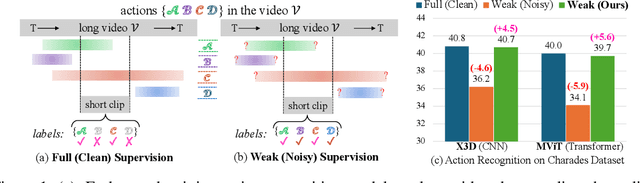
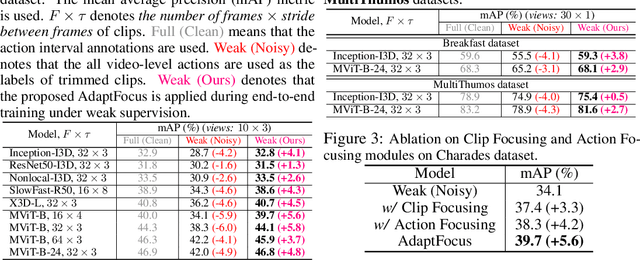
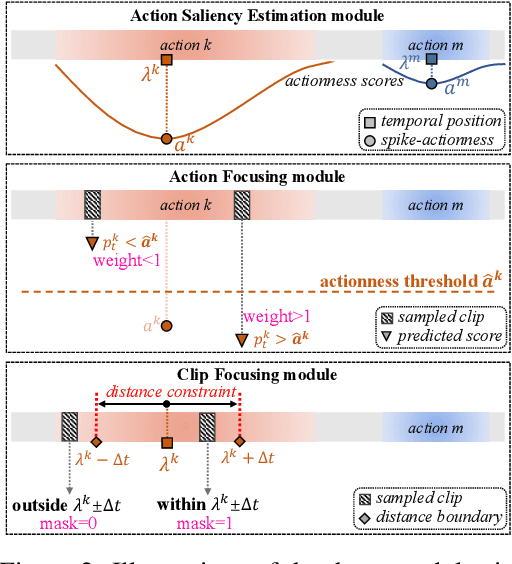

Developing end-to-end models for long-video action understanding tasks presents significant computational and memory challenges. Existing works generally build models on long-video features extracted by off-the-shelf action recognition models, which are trained on short-video datasets in different domains, making the extracted features suffer domain discrepancy. To avoid this, action recognition models can be end-to-end trained on clips, which are trimmed from long videos and labeled using action interval annotations. Such fully supervised annotations are expensive to collect. Thus, a weakly supervised method is needed for long-video action understanding at scale. Under the weak supervision setting, action labels are provided for the whole video without precise start and end times of the action clip. To this end, we propose an AdaFocus framework. AdaFocus estimates the spike-actionness and temporal positions of actions, enabling it to adaptively focus on action clips that facilitate better training without the need for precise annotations. Experiments on three long-video datasets show its effectiveness. Remarkably, on two of datasets, models trained with AdaFocus under weak supervision outperform those trained under full supervision. Furthermore, we form a weakly supervised feature extraction pipeline with our AdaFocus, which enables significant improvements on three long-video action understanding tasks.