Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeActor-Critic or Critic-Actor? A Tale of Two Time Scales
Paper and Code
Oct 10, 2022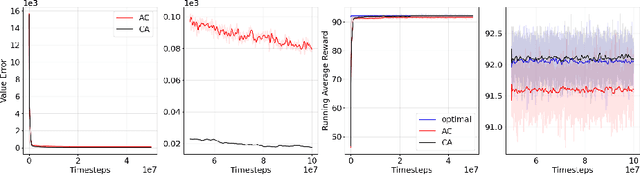
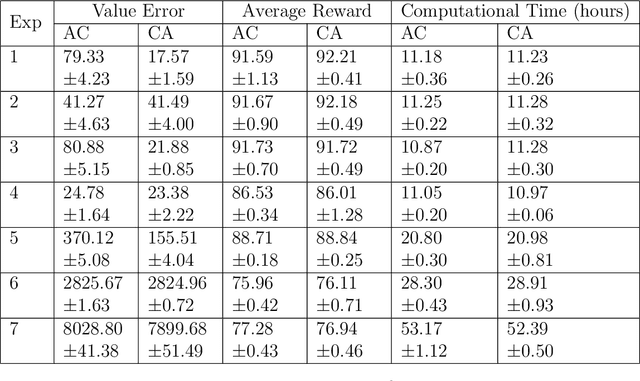
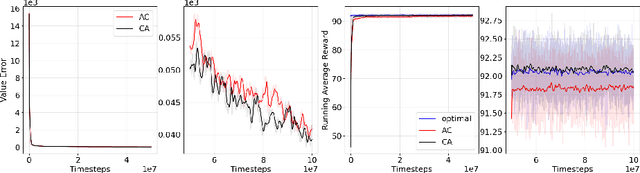
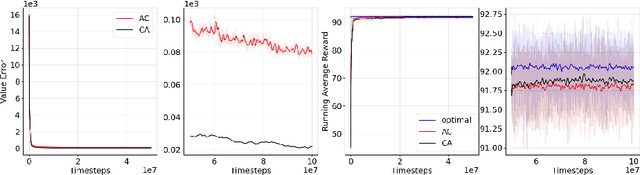
We revisit the standard formulation of tabular actor-critic algorithm as a two time-scale stochastic approximation with value function computed on a faster time-scale and policy computed on a slower time-scale. This emulates policy iteration. We begin by observing that reversal of the time scales will in fact emulate value iteration and is a legitimate algorithm. We compare the two empirically with and without function approximation (with both linear and nonlinear function approximators) and observe that our proposed critic-actor algorithm performs better empirically though with a marginal increase in the computational cost.
View paper on