 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeActor-Context-Actor Relation Network for Spatio-Temporal Action Localization
Paper and Code
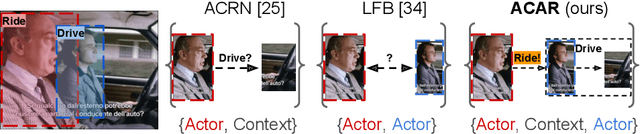
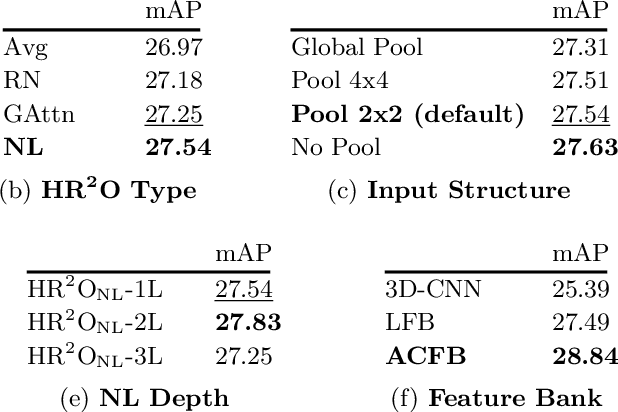
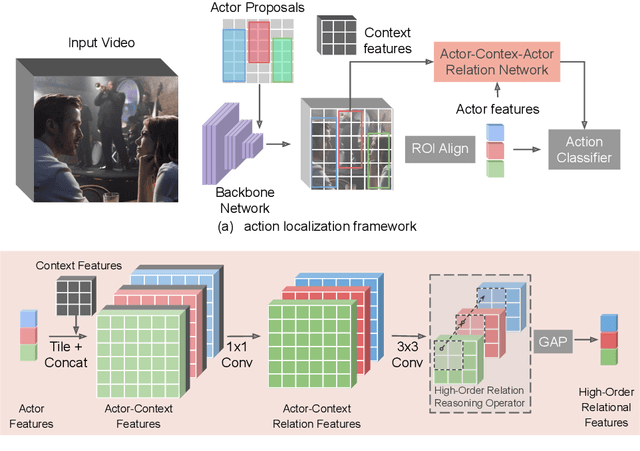
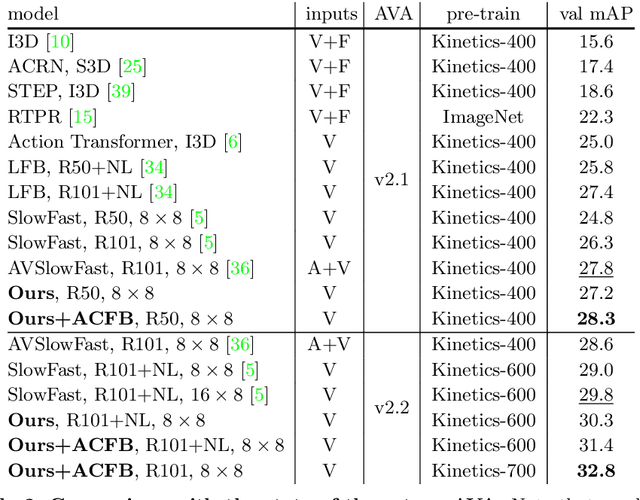
Localizing persons and recognizing their actions from videos is a challenging task towards high-level video understanding. Recent advances have been achieved by modeling either 'actor-actor' or 'actor-context' relations. However, such direct first-order relations are not sufficient for localizing actions in complicated scenes. Some actors might be indirectly related via objects or background context in the scene. Such indirect relations are crucial for determining the action labels but are mostly ignored by existing work. In this paper, we propose to explicitly model the Actor-Context-Actor Relation, which can capture indirect high-order supportive information for effectively reasoning actors' actions in complex scenes. To this end, we design an Actor-Context-Actor Relation Network (ACAR-Net) which builds upon a novel High-order Relation Reasoning Operator to model indirect relations for spatio-temporal action localization. Moreover, to allow utilizing more temporal contexts, we extend our framework with an Actor-Context Feature Bank for reasoning long-range high-order relations. Extensive experiments on AVA dataset validate the effectiveness of our ACAR-Net. Ablation studies show the advantages of modeling high-order relations over existing first-order relation reasoning methods. The proposed ACAR-Net is also the core module of our 1st place solution in AVA-Kinetics Crossover Challenge 2020. Training code and models will be available at https://github.com/Siyu-C/ACAR-Net.