 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeActive Reward Learning for Co-Robotic Vision Based Exploration in Bandwidth Limited Environments
Paper and Code
Mar 10, 2020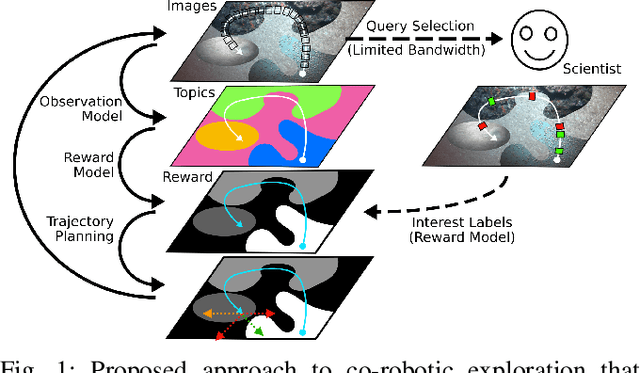
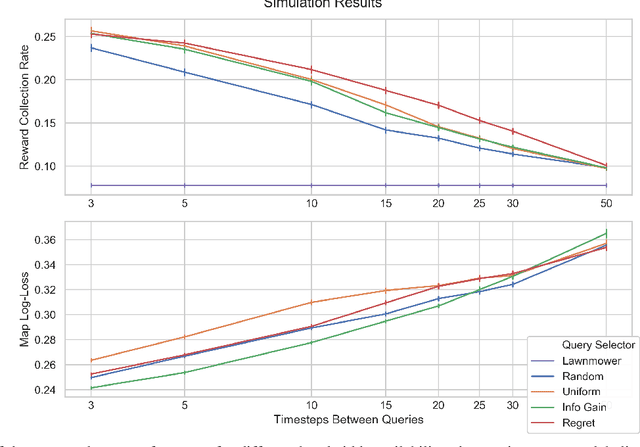
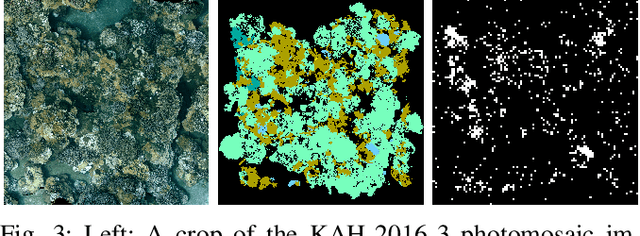
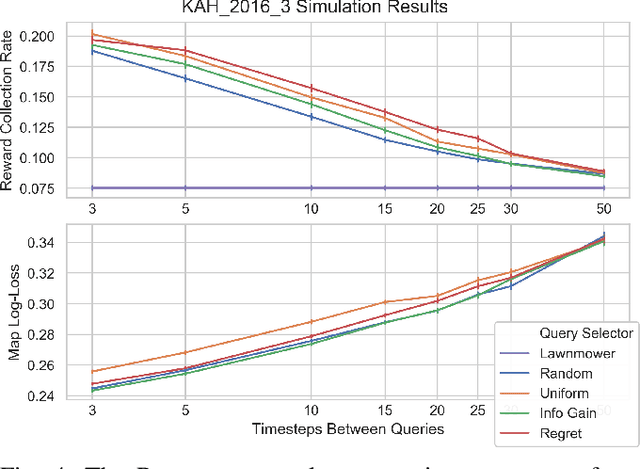
We present a novel POMDP problem formulation for a robot that must autonomously decide where to go to collect new and scientifically relevant images given a limited ability to communicate with its human operator. From this formulation we derive constraints and design principles for the observation model, reward model, and communication strategy of such a robot, exploring techniques to deal with the very high-dimensional observation space and scarcity of relevant training data. We introduce a novel active reward learning strategy based on making queries to help the robot minimize path "regret" online, and evaluate it for suitability in autonomous visual exploration through simulations. We demonstrate that, in some bandwidth-limited environments, this novel regret-based criterion enables the robotic explorer to collect up to 17% more reward per mission than the next-best criterion.