 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAction Keypoint Network for Efficient Video Recognition
Paper and Code
Jan 17, 2022
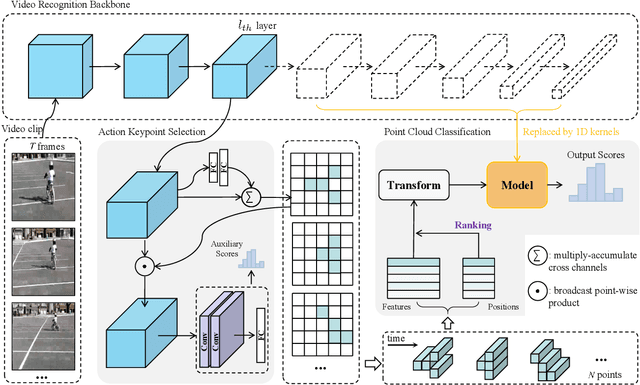
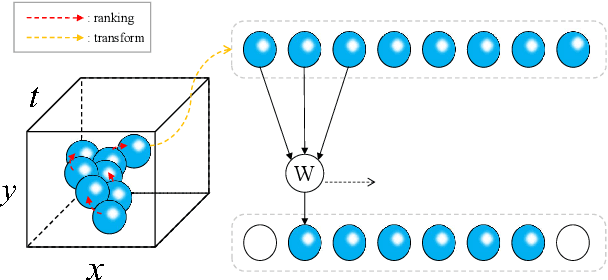
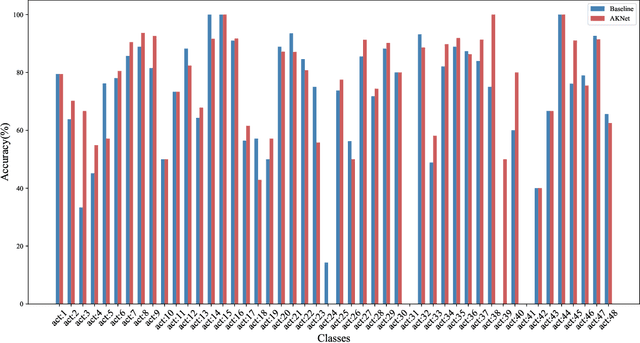
Reducing redundancy is crucial for improving the efficiency of video recognition models. An effective approach is to select informative content from the holistic video, yielding a popular family of dynamic video recognition methods. However, existing dynamic methods focus on either temporal or spatial selection independently while neglecting a reality that the redundancies are usually spatial and temporal, simultaneously. Moreover, their selected content is usually cropped with fixed shapes, while the realistic distribution of informative content can be much more diverse. With these two insights, this paper proposes to integrate temporal and spatial selection into an Action Keypoint Network (AK-Net). From different frames and positions, AK-Net selects some informative points scattered in arbitrary-shaped regions as a set of action keypoints and then transforms the video recognition into point cloud classification. AK-Net has two steps, i.e., the keypoint selection and the point cloud classification. First, it inputs the video into a baseline network and outputs a feature map from an intermediate layer. We view each pixel on this feature map as a spatial-temporal point and select some informative keypoints using self-attention. Second, AK-Net devises a ranking criterion to arrange the keypoints into an ordered 1D sequence. Consequentially, AK-Net brings two-fold benefits for efficiency: The keypoint selection step collects informative content within arbitrary shapes and increases the efficiency for modeling spatial-temporal dependencies, while the point cloud classification step further reduces the computational cost by compacting the convolutional kernels. Experimental results show that AK-Net can consistently improve the efficiency and performance of baseline methods on several video recognition benchmarks.