 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAcoustic Modeling for End-to-End Empathetic Dialogue Speech Synthesis Using Linguistic and Prosodic Contexts of Dialogue History
Paper and Code
Jun 16, 2022

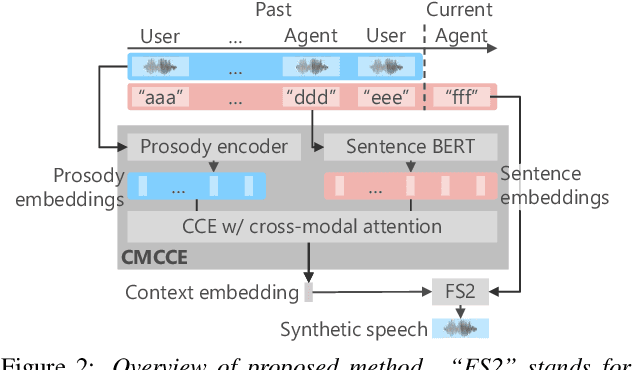

We propose an end-to-end empathetic dialogue speech synthesis (DSS) model that considers both the linguistic and prosodic contexts of dialogue history. Empathy is the active attempt by humans to get inside the interlocutor in dialogue, and empathetic DSS is a technology to implement this act in spoken dialogue systems. Our model is conditioned by the history of linguistic and prosody features for predicting appropriate dialogue context. As such, it can be regarded as an extension of the conventional linguistic-feature-based dialogue history modeling. To train the empathetic DSS model effectively, we investigate 1) a self-supervised learning model pretrained with large speech corpora, 2) a style-guided training using a prosody embedding of the current utterance to be predicted by the dialogue context embedding, 3) a cross-modal attention to combine text and speech modalities, and 4) a sentence-wise embedding to achieve fine-grained prosody modeling rather than utterance-wise modeling. The evaluation results demonstrate that 1) simply considering prosodic contexts of the dialogue history does not improve the quality of speech in empathetic DSS and 2) introducing style-guided training and sentence-wise embedding modeling achieves higher speech quality than that by the conventional method.