 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAcoustic-aware Non-autoregressive Spell Correction with Mask Sample Decoding
Paper and Code
Oct 16, 2022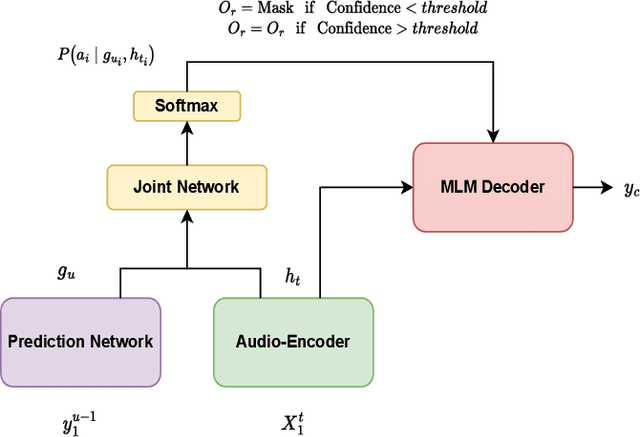
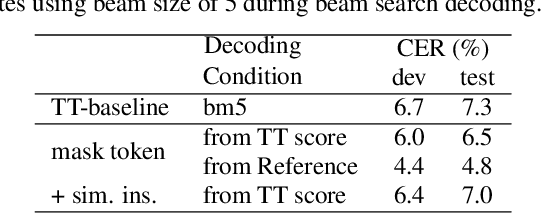

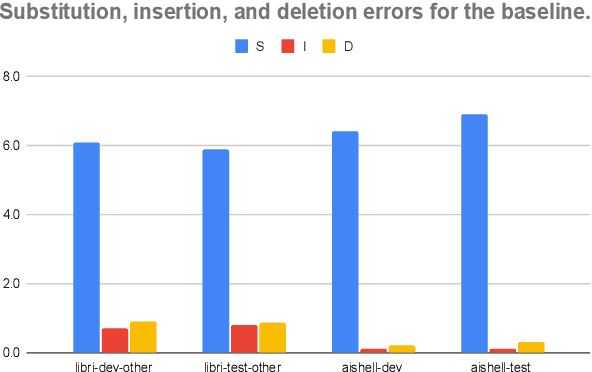
Masked language model (MLM) has been widely used for understanding tasks, e.g. BERT. Recently, MLM has also been used for generation tasks. The most popular one in speech is using Mask-CTC for non-autoregressive speech recognition. In this paper, we take one step further, and explore the possibility of using MLM as a non-autoregressive spell correction (SC) model for transformer-transducer (TT), denoted as MLM-SC. Our initial experiments show that MLM-SC provides no improvements on Librispeech data. The problem might be the choice of modeling units (word pieces) and the inaccuracy of the TT confidence scores for English data. To solve the problem, we propose a mask sample decoding (MS-decode) method where the masked tokens can have the choice of being masked or not to compensate for the inaccuracy. As a result, we reduce the WER of a streaming TT from 7.6% to 6.5% on the Librispeech test-other data and the CER from 7.3% to 6.1% on the Aishell test data, respectively.