 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAchieving Sample-Efficient and Online-Training-Safe Deep Reinforcement Learning with Base Controllers
Paper and Code
Nov 24, 2020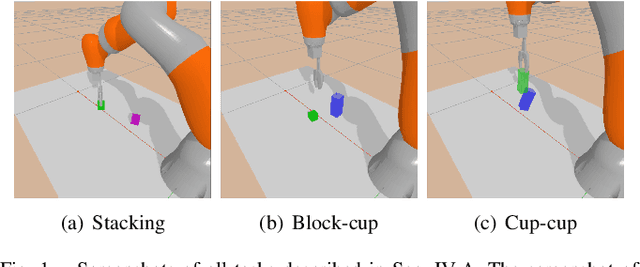
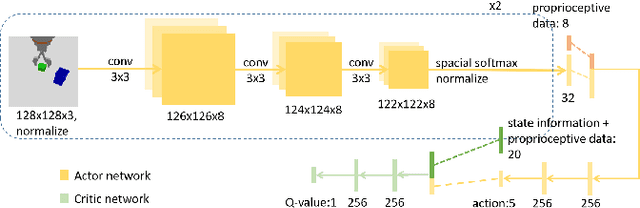
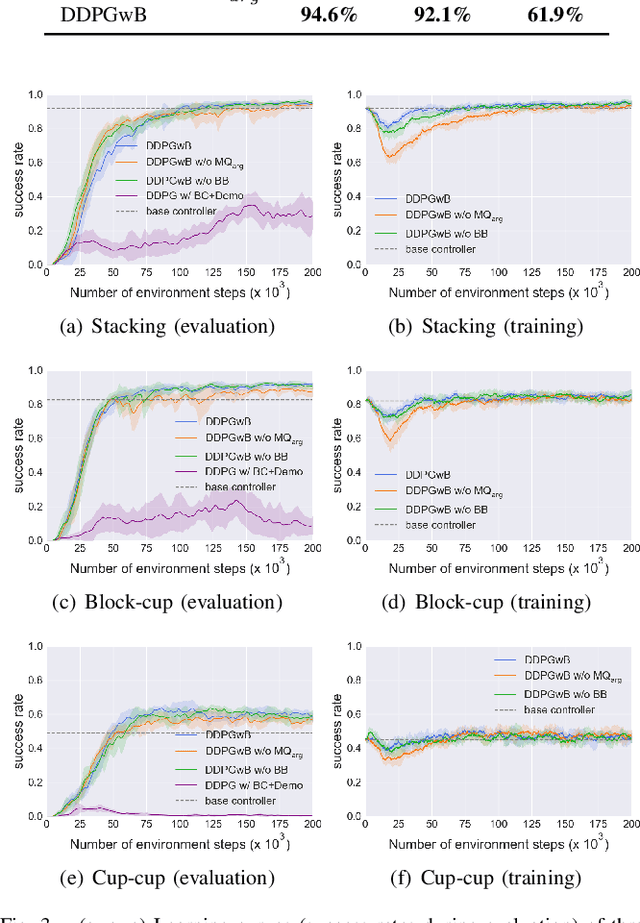
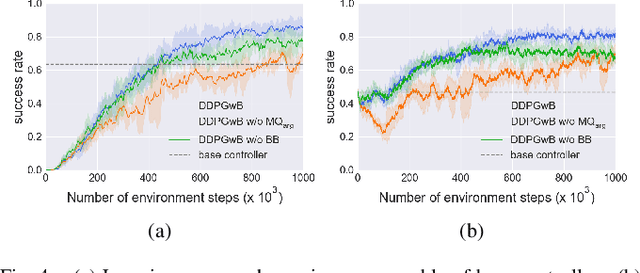
Application of Deep Reinforcement Learning (DRL) algorithms in real-world robotic tasks faces many challenges. On the one hand, reward-shaping for complex tasks is difficult and may result in sub-optimal performances. On the other hand, a sparse-reward setting renders exploration inefficient, and exploration using physical robots is of high-cost and unsafe. In this paper we propose a method of learning challenging sparse-reward tasks utilizing existing controllers. Built upon Deep Deterministic Policy Gradients (DDPG), our algorithm incorporates the controllers into stages of exploration, Q-value estimation as well as policy update. Through experiments ranging from stacking blocks to cups, we present a straightforward way of synthesizing these controllers, and show that the learned state-based or image-based policies steadily outperform them. Compared to previous works of learning from demonstrations, our method improves sample efficiency by orders of magnitude and can learn online in a safe manner. Overall, our method bears the potential of leveraging existing industrial robot manipulation systems to build more flexible and intelligent controllers.