 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAccumulated Decoupled Learning: Mitigating Gradient Staleness in Inter-Layer Model Parallelization
Paper and Code
Dec 03, 2020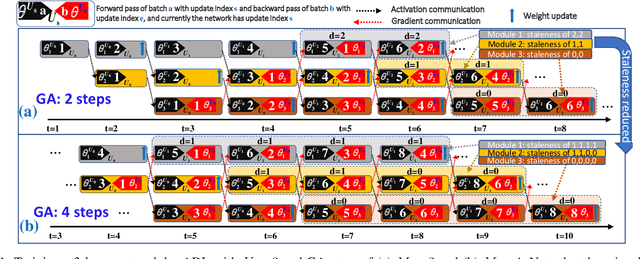
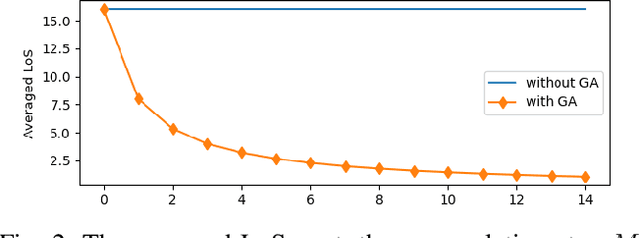
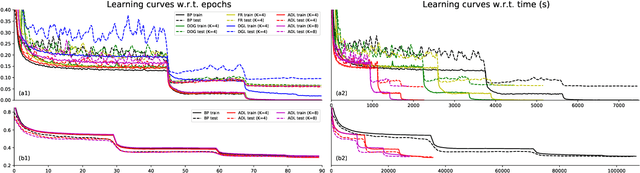
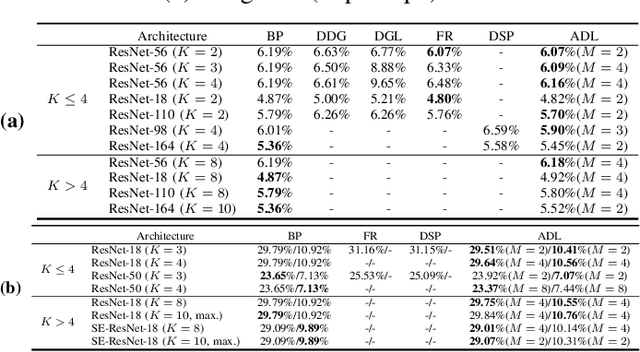
Decoupled learning is a branch of model parallelism which parallelizes the training of a network by splitting it depth-wise into multiple modules. Techniques from decoupled learning usually lead to stale gradient effect because of their asynchronous implementation, thereby causing performance degradation. In this paper, we propose an accumulated decoupled learning (ADL) which incorporates the gradient accumulation technique to mitigate the stale gradient effect. We give both theoretical and empirical evidences regarding how the gradient staleness can be reduced. We prove that the proposed method can converge to critical points, i.e., the gradients converge to 0, in spite of its asynchronous nature. Empirical validation is provided by training deep convolutional neural networks to perform classification tasks on CIFAR-10 and ImageNet datasets. The ADL is shown to outperform several state-of-the-arts in the classification tasks, and is the fastest among the compared methods.