 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAccelerated Primal-Dual Algorithms for Distributed Smooth Convex Optimization over Networks
Paper and Code
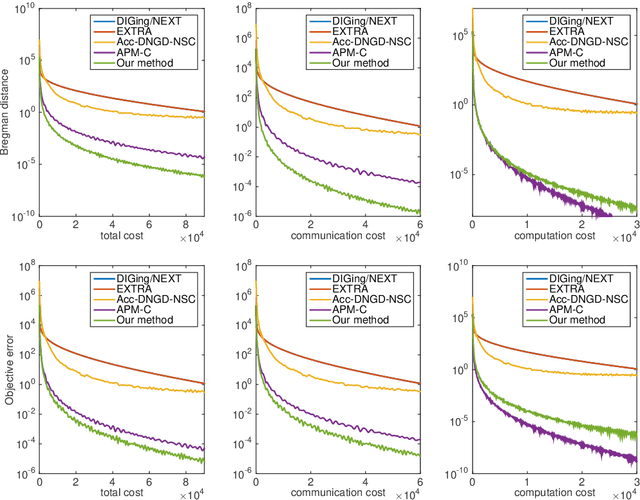
This paper proposes a novel family of primal-dual-based distributed algorithms for smooth, convex, multi-agent optimization over networks that uses only gradient information and gossip communications. The algorithms can also employ acceleration on the computation and communications. We provide a unified analysis of their convergence rate, measured in terms of the Bregman distance associated to the saddle point reformation of the distributed optimization problem. When acceleration is employed, the rate is shown to be optimal, in the sense that it matches (under the proposed metric) existing complexity lower bounds of distributed algorithms applicable to such a class of problem and using only gradient information and gossip communications. Preliminary numerical results on distributed least-square regression problems show that the proposed algorithm compares favorably on existing distributed schemes.