 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAccelerated Linear Convergence of Stochastic Momentum Methods in Wasserstein Distances
Paper and Code
Jan 22, 2019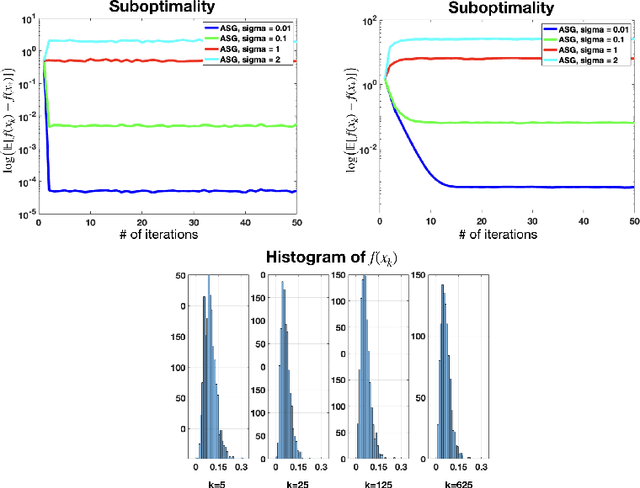
Momentum methods such as Polyak's heavy ball (HB) method, Nesterov's accelerated gradient (AG) as well as accelerated projected gradient (APG) method have been commonly used in machine learning practice, but their performance is quite sensitive to noise in the gradients. We study these methods under a first-order stochastic oracle model where noisy estimates of the gradients are available. For strongly convex problems, we show that the distribution of the iterates of AG converges with the accelerated $O(\sqrt{\kappa}\log(1/\varepsilon))$ linear rate to a ball of radius $\varepsilon$ centered at a unique invariant distribution in the 1-Wasserstein metric where $\kappa$ is the condition number as long as the noise variance is smaller than an explicit upper bound we can provide. Our analysis also certifies linear convergence rates as a function of the stepsize, momentum parameter and the noise variance; recovering the accelerated rates in the noiseless case and quantifying the level of noise that can be tolerated to achieve a given performance. In the special case of strongly convex quadratic objectives, we can show accelerated linear rates in the $p$-Wasserstein metric for any $p\geq 1$ with improved sensitivity to noise for both AG and HB through a non-asymptotic analysis under some additional assumptions on the noise structure. Our analysis for HB and AG also leads to improved non-asymptotic convergence bounds in suboptimality for both deterministic and stochastic settings which is of independent interest. To the best of our knowledge, these are the first linear convergence results for stochastic momentum methods under the stochastic oracle model. We also extend our results to the APG method and weakly convex functions showing accelerated rates when the noise magnitude is sufficiently small.