 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Vietnamese Dataset for Evaluating Machine Reading Comprehension
Paper and Code
Oct 02, 2020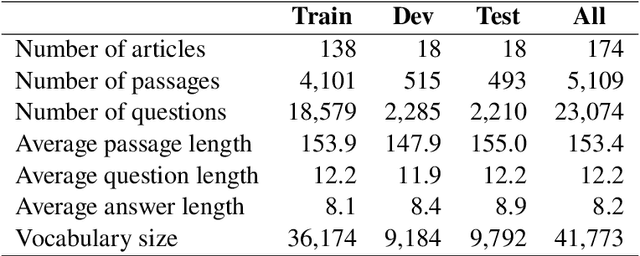
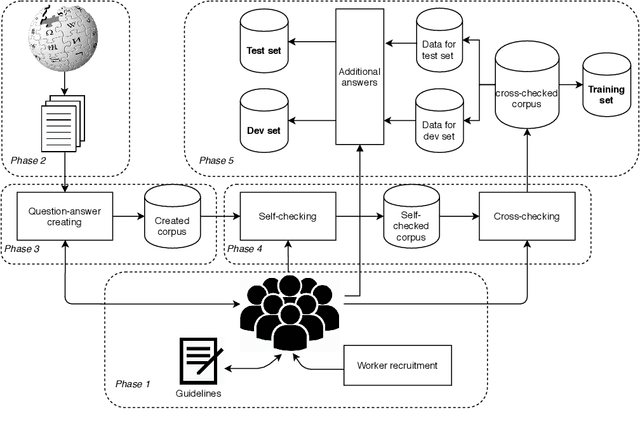
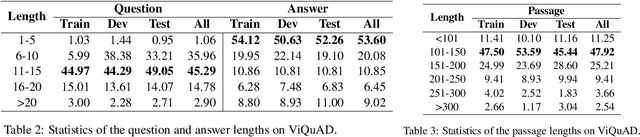
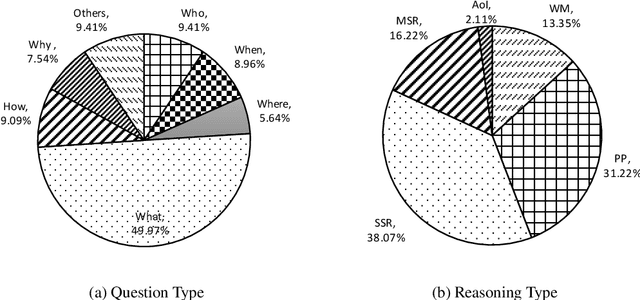
Over 97 million inhabitants speak Vietnamese as the native language in the world. However, there are few research studies on machine reading comprehension (MRC) in Vietnamese, the task of understanding a document or text, and answering questions related to it. Due to the lack of benchmark datasets for Vietnamese, we present the Vietnamese Question Answering Dataset (ViQuAD), a new dataset for the low-resource language as Vietnamese to evaluate MRC models. This dataset comprises over 23,000 human-generated question-answer pairs based on 5,109 passages of 174 Vietnamese articles from Wikipedia. In particular, we propose a new process of dataset creation for Vietnamese MRC. Our in-depth analyses illustrate that our dataset requires abilities beyond simple reasoning like word matching and demands complicate reasoning such as single-sentence and multiple-sentence inferences. Besides, we conduct experiments on state-of-the-art MRC methods in English and Chinese as the first experimental models on ViQuAD, which will be compared to further models. We also estimate human performances on the dataset and compare it to the experimental results of several powerful machine models. As a result, the substantial differences between humans and the best model performances on the dataset indicate that improvements can be explored on ViQuAD through future research. Our dataset is freely available to encourage the research community to overcome challenges in Vietnamese MRC.