 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Unifying Network Architecture for Semi-Structured Deep Distributional Learning
Paper and Code

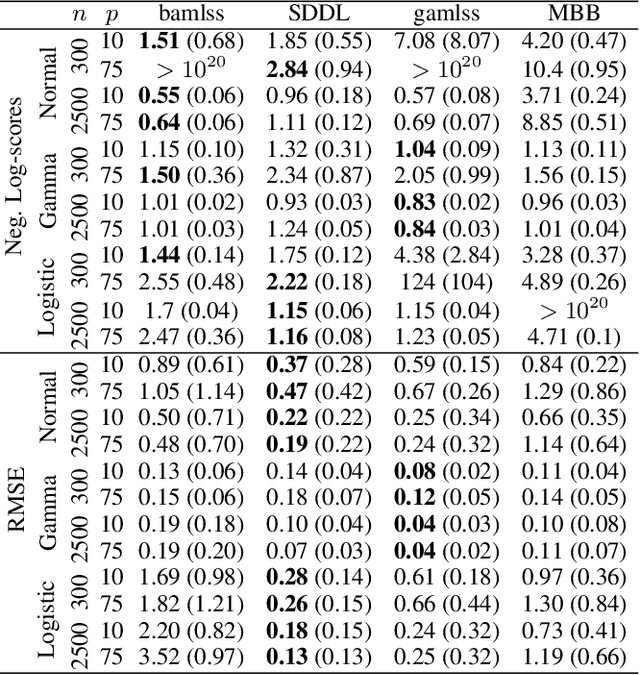


We propose a unifying network architecture for deep distributional learning in which entire distributions can be learned in a general framework of interpretable regression models and deep neural networks. Previous approaches that try to combine advanced statistical models and deep neural networks embed the neural network part as a predictor in an additive regression model. In contrast, our approach estimates the statistical model part within a unifying neural network by projecting the deep learning model part into the orthogonal complement of the regression model predictor. This facilitates both estimation and interpretability in high-dimensional settings. We identify appropriate default penalties that can also be treated as prior distribution assumptions in the Bayesian version of our network architecture. We consider several use-cases in experiments with synthetic data and real world applications to demonstrate the full efficacy of our approach.