 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Unified Analysis of Random Fourier Features
Paper and Code
Jun 24, 2018
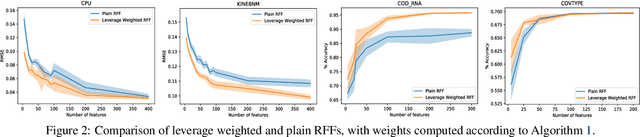
We provide the first unified theoretical analysis of supervised learning with random Fourier features, covering different types of loss functions characteristic to kernel methods developed for this setting. More specifically, we investigate learning with squared error and Lipschitz continuous loss functions and give the sharpest expected risk convergence rates for problems in which random Fourier features are sampled either using the spectral measure corresponding to a shift-invariant kernel or the ridge leverage score function proposed in~\cite{avron2017random}. The trade-off between the number of features and the expected risk convergence rate is expressed in terms of the regularization parameter and the effective dimension of the problem. While the former can effectively capture the complexity of the target hypothesis, the latter is known for expressing the fine structure of the kernel with respect to the marginal distribution of a data generating process~\cite{caponnetto2007optimal}. In addition to our theoretical results, we propose an approximate leverage score sampler for large scale problems and show that it can be significantly more effective than the spectral measure sampler.