 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Two-Time-Scale Stochastic Optimization Framework with Applications in Control and Reinforcement Learning
Paper and Code
Oct 01, 2021
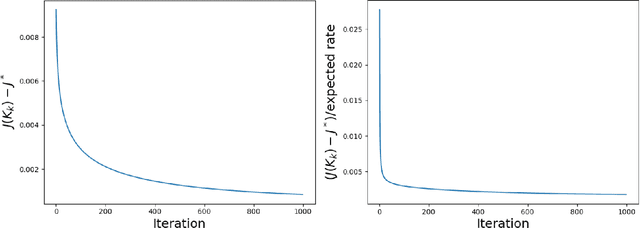
We study a novel two-time-scale stochastic gradient method for solving optimization problems where the gradient samples are generated from a time-varying Markov random process parameterized by the underlying optimization variable. These time-varying samples make the stochastic gradient biased and dependent, which can potentially lead to the divergence of the iterates. To address this issue, we consider a two-time-scale update scheme, where one scale is used to estimate the true gradient from the Markovian samples and the other scale is used to update the decision variable with the estimated gradient. While these two iterates are implemented simultaneously, the former is updated "faster" (using bigger step sizes) than the latter (using smaller step sizes). Our first contribution is to characterize the finite-time complexity of the proposed two-time-scale stochastic gradient method. In particular, we provide explicit formulas for the convergence rates of this method under different objective functions, namely, strong convexity, convexity, non-convexity under the PL condition, and general non-convexity. Our second contribution is to apply our framework to study the performance of the popular actor-critic methods in solving stochastic control and reinforcement learning problems. First, we study an online natural actor-critic algorithm for the linear-quadratic regulator and show that a convergence rate of $\mathcal{O}(k^{-2/3})$ is achieved. This is the first time such a result is known in the literature. Second, we look at the standard online actor-critic algorithm over finite state and action spaces and derive a convergence rate of $\mathcal{O}(k^{-2/5})$, which recovers the best known rate derived specifically for this problem. Finally, we support our theoretical analysis with numerical simulations where the convergence rate is visualized.