 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Two-Stage Method for Text Line Detection in Historical Documents
Paper and Code
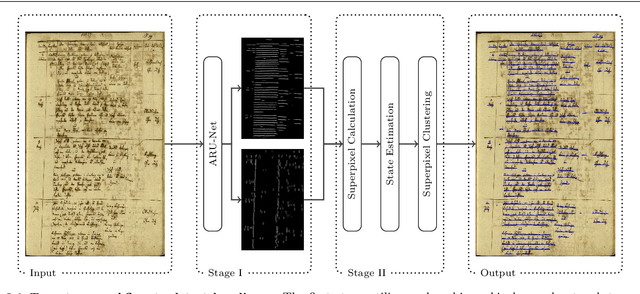
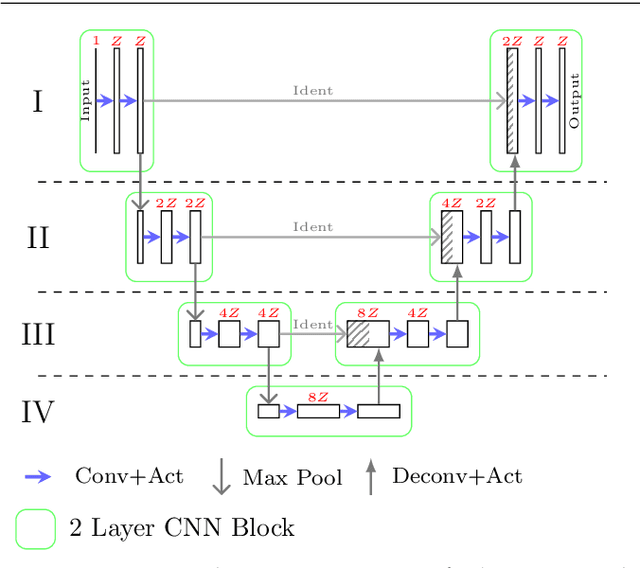
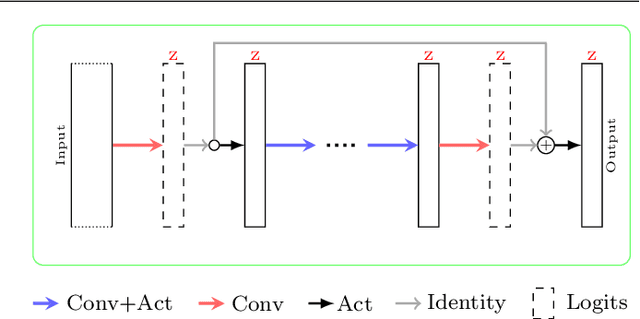
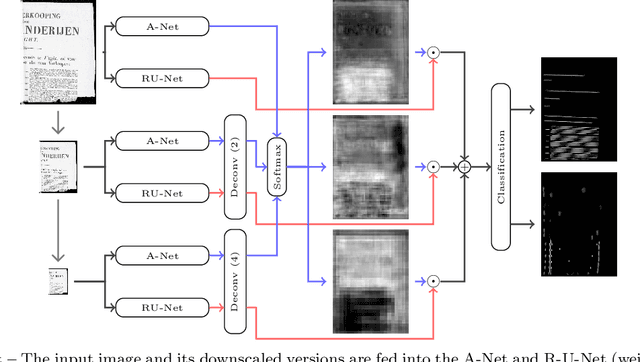
This work presents a two-stage text line detection method for historical documents. In a first stage, a deep neural network called ARU-Net labels pixels to belong to one of the three classes: baseline, separator or other. The separator class marks beginning and end of each text line. The ARU-Net is trainable from scratch with manageably few manually annotated example images (less than 50). This is achieved by utilizing data augmentation strategies. The network predictions are used as input for the second stage which performs a bottom-up clustering to build baselines. The developed method is capable of handling complex layouts as well as curved and arbitrarily oriented text lines. It substantially outperforms current state-of-the-art approaches. For example, for the complex track of the cBAD: ICDAR2017 Competiton on Baseline Detection the F-value is increased from 0.859 to 0.922. The framework to train and run the ARU-Net is open source.