 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA two-stage 3D Unet framework for multi-class segmentation on full resolution image
Paper and Code
Apr 12, 2018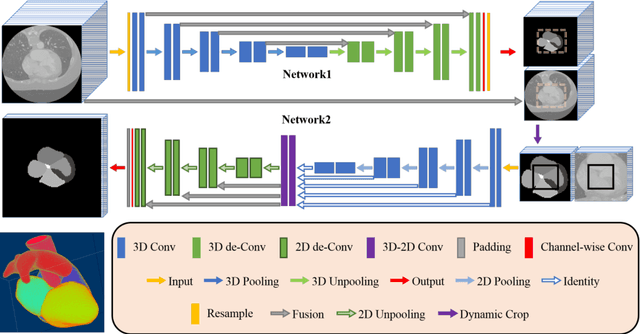

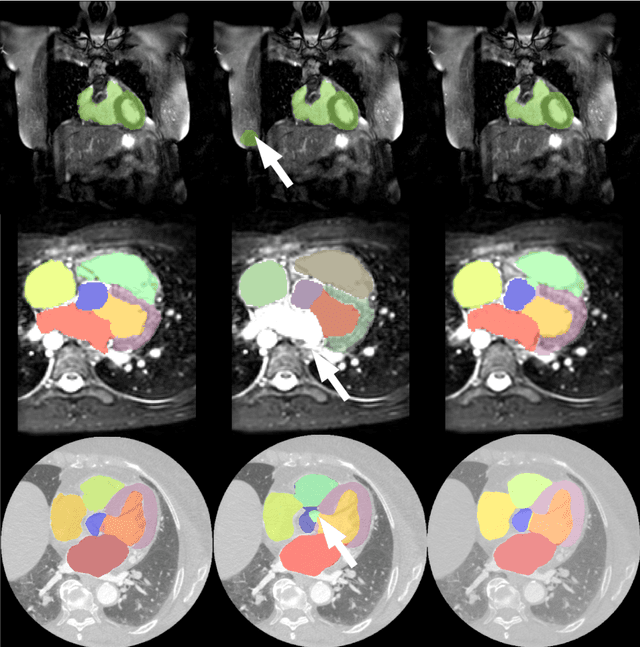
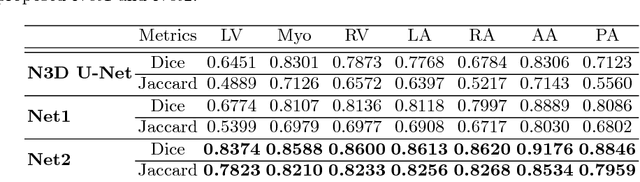
Deep convolutional neural networks (CNNs) have been intensively used for multi-class segmentation of data from different modalities and achieved state-of-the-art performances. However, a common problem when dealing with large, high resolution 3D data is that the volumes input into the deep CNNs has to be either cropped or downsampled due to limited memory capacity of computing devices. These operations lead to loss of resolution and increment of class imbalance in the input data batches, which can downgrade the performances of segmentation algorithms. Inspired by the architecture of image super-resolution CNN (SRCNN) and self-normalization network (SNN), we developed a two-stage modified Unet framework that simultaneously learns to detect a ROI within the full volume and to classify voxels without losing the original resolution. Experiments on a variety of multi-modal volumes demonstrated that, when trained with a simply weighted dice coefficients and our customized learning procedure, this framework shows better segmentation performances than state-of-the-art Deep CNNs with advanced similarity metrics.