 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Systematic Characterization of Sampling Algorithms for Open-ended Language Generation
Paper and Code
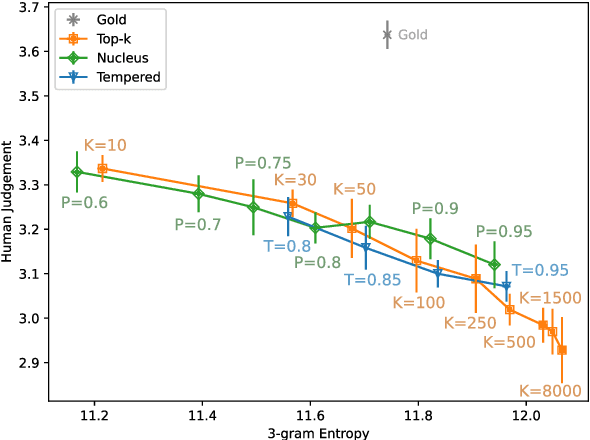
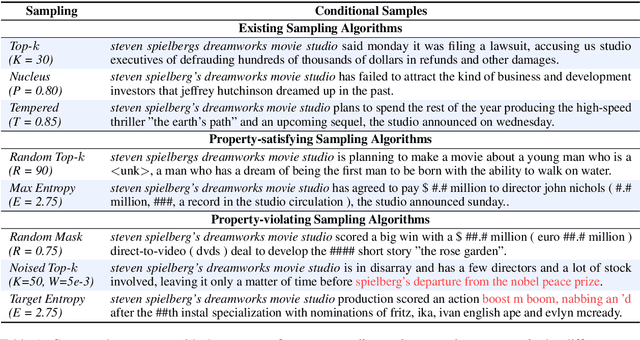
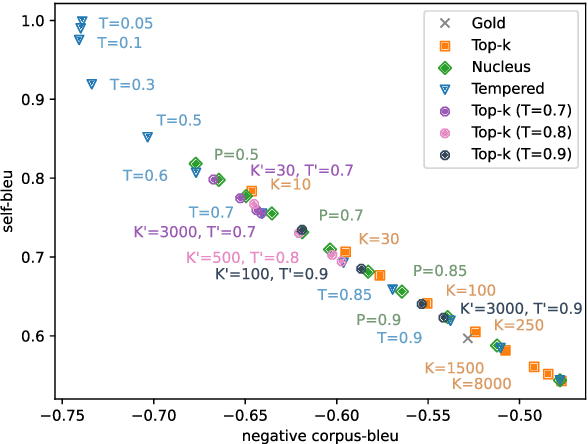

This work studies the widely adopted ancestral sampling algorithms for auto-regressive language models, which is not widely studied in the literature. We use the quality-diversity (Q-D) trade-off to investigate three popular sampling algorithms (top-k, nucleus and tempered sampling). We focus on the task of open-ended language generation. We first show that the existing sampling algorithms have similar performance. After carefully inspecting the transformations defined by different sampling algorithms, we identify three key properties that are shared among them: entropy reduction, order preservation, and slope preservation. To validate the importance of the identified properties, we design two sets of new sampling algorithms: one set in which each algorithm satisfies all three properties, and one set in which each algorithm violates at least one of the properties. We compare their performance with existing sampling algorithms, and find that violating the identified properties could lead to drastic performance degradation, as measured by the Q-D trade-off. On the other hand, we find that the set of sampling algorithms that satisfies these properties performs on par with the existing sampling algorithms. Our data and code are available at https://github.com/moinnadeem/characterizing-sampling-algorithms