Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Survey on Out-of-Distribution Evaluation of Neural NLP Models
Paper and Code
Jun 27, 2023

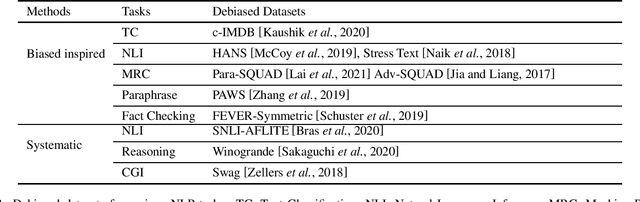

Adversarial robustness, domain generalization and dataset biases are three active lines of research contributing to out-of-distribution (OOD) evaluation on neural NLP models. However, a comprehensive, integrated discussion of the three research lines is still lacking in the literature. In this survey, we 1) compare the three lines of research under a unifying definition; 2) summarize the data-generating processes and evaluation protocols for each line of research; and 3) emphasize the challenges and opportunities for future work.
* IJCAI2023 Survey Track
View paper on