Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Survey on Neural Machine Reading Comprehension
Paper and Code
Jun 10, 2019
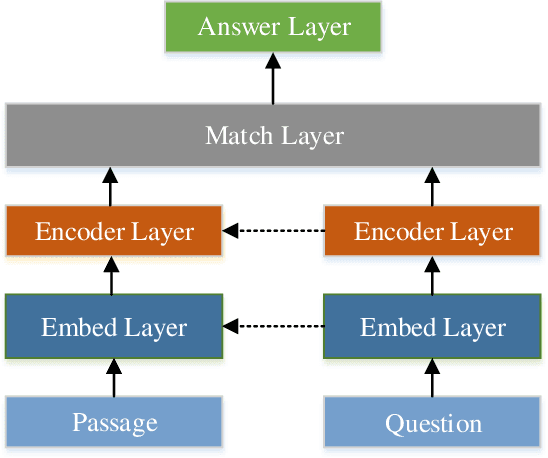
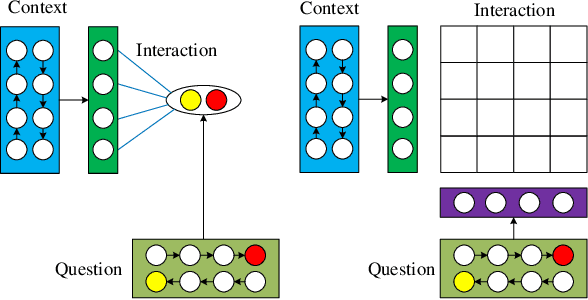
Enabling a machine to read and comprehend the natural language documents so that it can answer some questions remains an elusive challenge. In recent years, the popularity of deep learning and the establishment of large-scale datasets have both promoted the prosperity of Machine Reading Comprehension. This paper aims to present how to utilize the Neural Network to build a Reader and introduce some classic models, analyze what improvements they make. Further, we also point out the defects of existing models and future research directions
View paper on