 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Survey on Machine Reading Comprehension Systems
Paper and Code
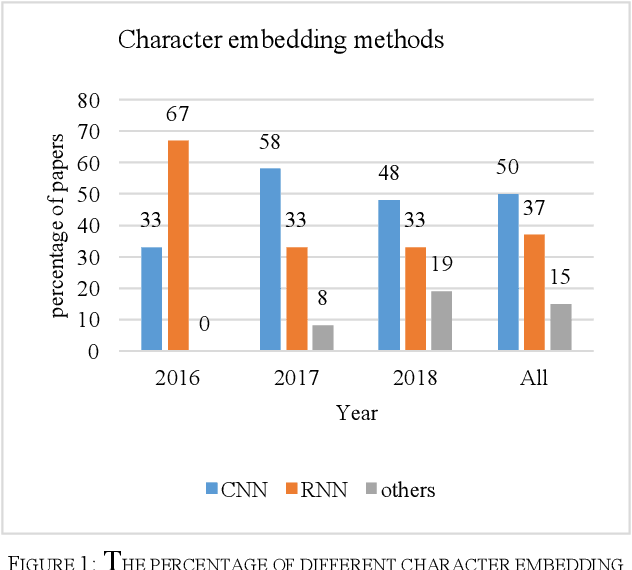
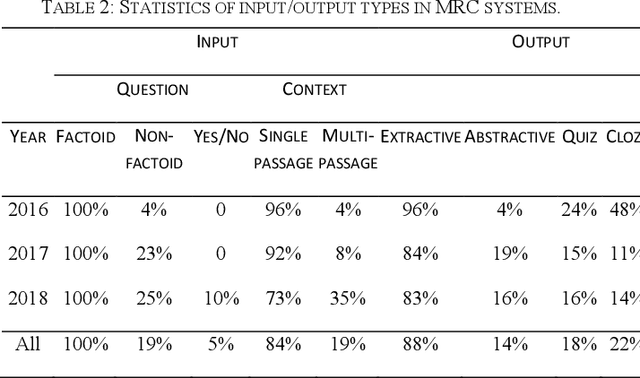
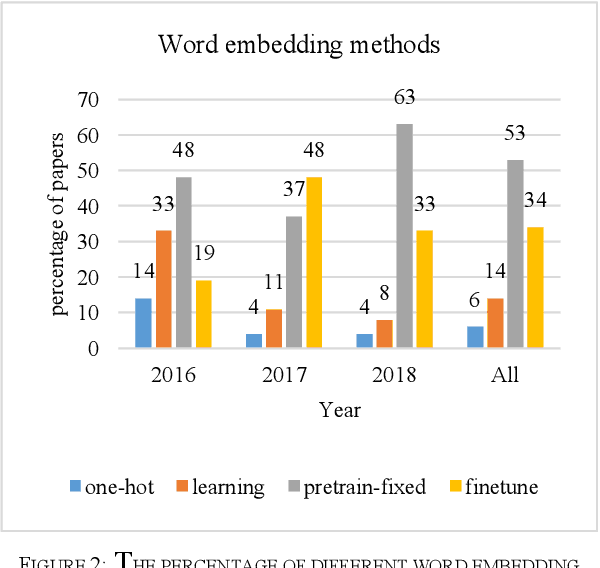

Machine reading comprehension is a challenging task and hot topic in natural language processing. Its goal is to develop systems to answer the questions regarding a given context. In this paper, we present a comprehensive survey on different aspects of machine reading comprehension systems, including their approaches, structures, input/outputs, and research novelties. We illustrate the recent trends in this field based on 124 reviewed papers from 2016 to 2018. Our investigations demonstrate that the focus of research has changed in recent years from answer extraction to answer generation, from single to multi-document reading comprehension, and from learning from scratch to using pre-trained embeddings. We also discuss the popular datasets and the evaluation metrics in this field. The paper ends with investigating the most cited papers and their contributions.