 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Survey on Efficient Vision-Language Models
Paper and Code


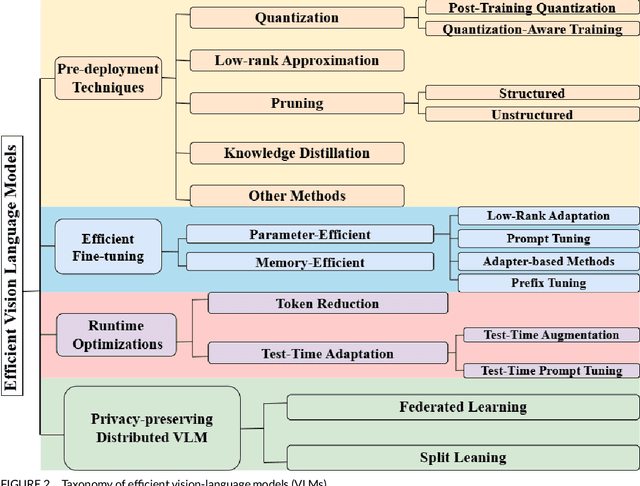

Vision-language models (VLMs) integrate visual and textual information, enabling a wide range of applications such as image captioning and visual question answering, making them crucial for modern AI systems. However, their high computational demands pose challenges for real-time applications. This has led to a growing focus on developing efficient vision language models. In this survey, we review key techniques for optimizing VLMs on edge and resource-constrained devices. We also explore compact VLM architectures, frameworks and provide detailed insights into the performance-memory trade-offs of efficient VLMs. Furthermore, we establish a GitHub repository at https://github.com/MPSCUMBC/Efficient-Vision-Language-Models-A-Survey to compile all surveyed papers, which we will actively update. Our objective is to foster deeper research in this area.