 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA survey on domain adaptation theory
Paper and Code
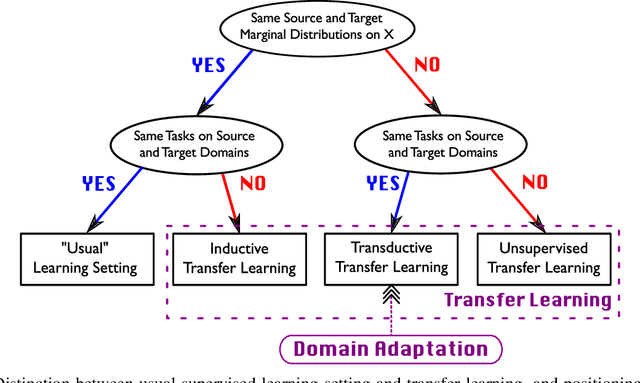
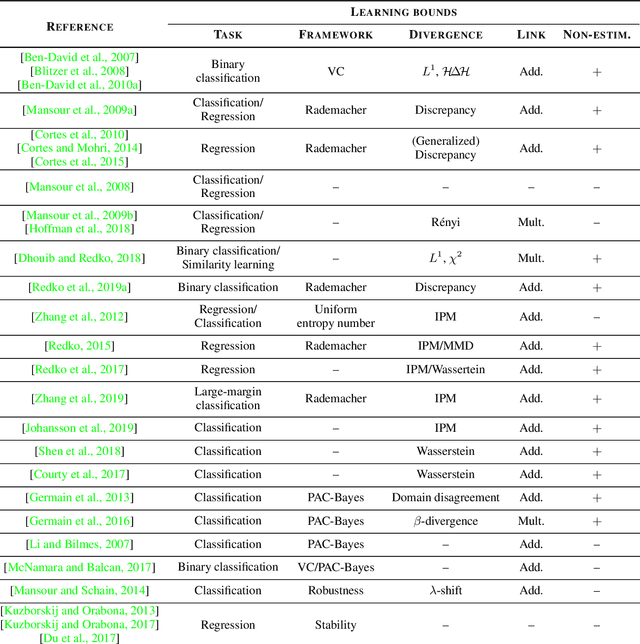
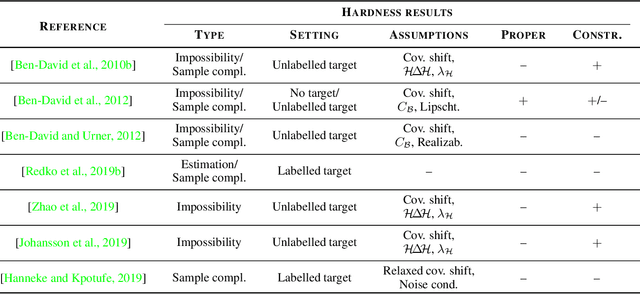
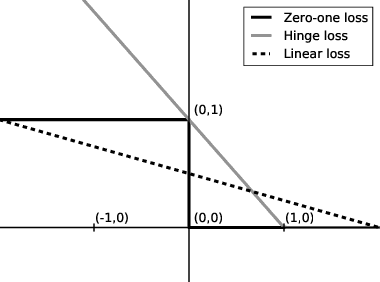
All famous machine learning algorithms that correspond to both supervised and semi-supervised learning work well only under a common assumption: training and test data follow the same distribution. When the distribution changes, most statistical models must be reconstructed from new collected data that, for some applications, may be costly or impossible to get. Therefore, it became necessary to develop approaches that reduce the need and the effort of obtaining new labeled samples by exploiting data available in related areas and using it further in similar fields. This has given rise to a new machine learning framework called transfer learning: a learning setting inspired by the capability of a human being to extrapolate knowledge across tasks to learn more efficiently. Despite a large amount of different transfer learning scenarios, the main objective of this survey is to provide an overview of the state-of-the-art theoretical results in a specific and arguably the most popular sub-field of transfer learning called domain adaptation. In this sub-field, the data distribution is assumed to change across the training and the test data while the learning task remains the same. We provide a first up-to-date description of existing results related to domain adaptation problem that cover learning bounds based on different statistical learning frameworks.