 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Surprising Linear Relationship Predicts Test Performance in Deep Networks
Paper and Code
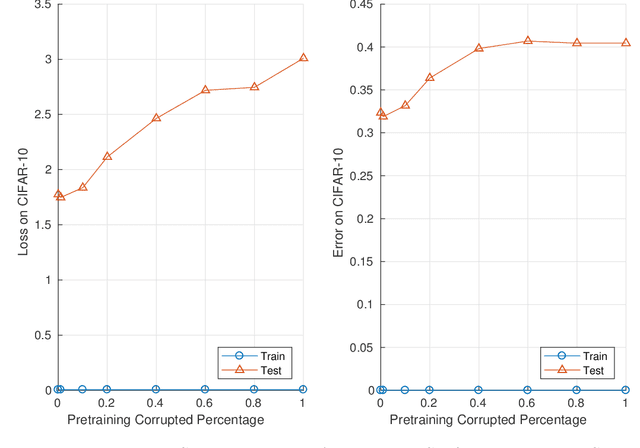
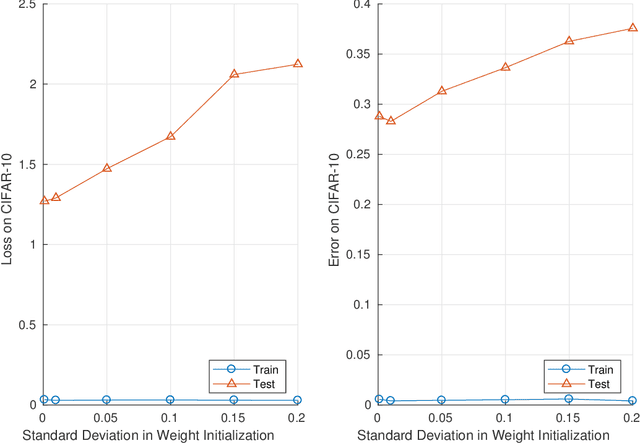
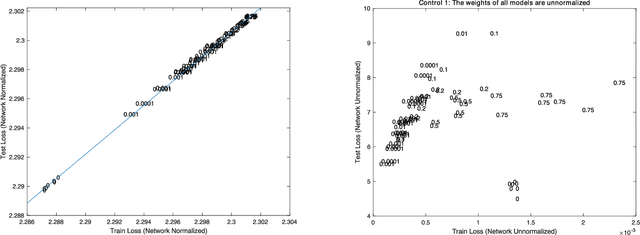
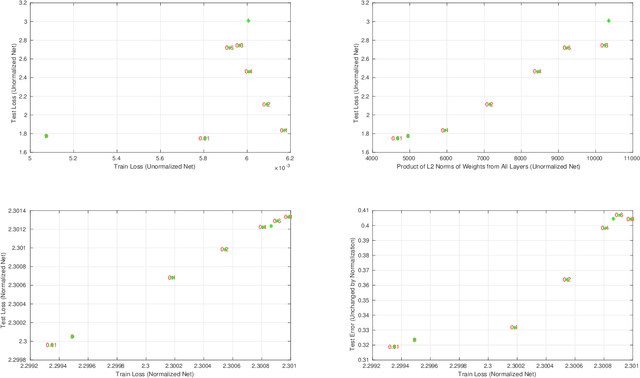
Given two networks with the same training loss on a dataset, when would they have drastically different test losses and errors? Better understanding of this question of generalization may improve practical applications of deep networks. In this paper we show that with cross-entropy loss it is surprisingly simple to induce significantly different generalization performances for two networks that have the same architecture, the same meta parameters and the same training error: one can either pretrain the networks with different levels of "corrupted" data or simply initialize the networks with weights of different Gaussian standard deviations. A corollary of recent theoretical results on overfitting shows that these effects are due to an intrinsic problem of measuring test performance with a cross-entropy/exponential-type loss, which can be decomposed into two components both minimized by SGD -- one of which is not related to expected classification performance. However, if we factor out this component of the loss, a linear relationship emerges between training and test losses. Under this transformation, classical generalization bounds are surprisingly tight: the empirical/training loss is very close to the expected/test loss. Furthermore, the empirical relation between classification error and normalized cross-entropy loss seem to be approximately monotonic