 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Single 2D Pose with Context is Worth Hundreds for 3D Human Pose Estimation
Paper and Code
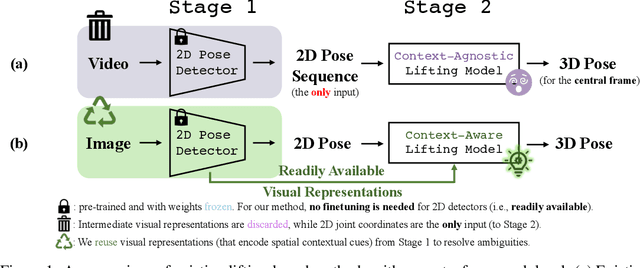
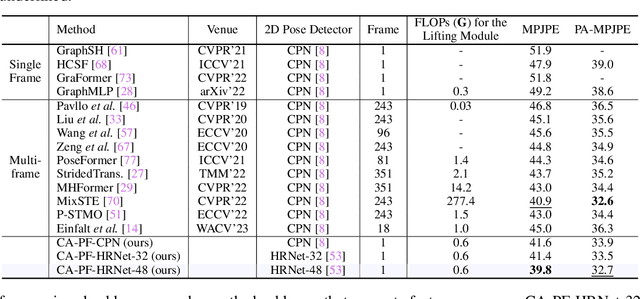
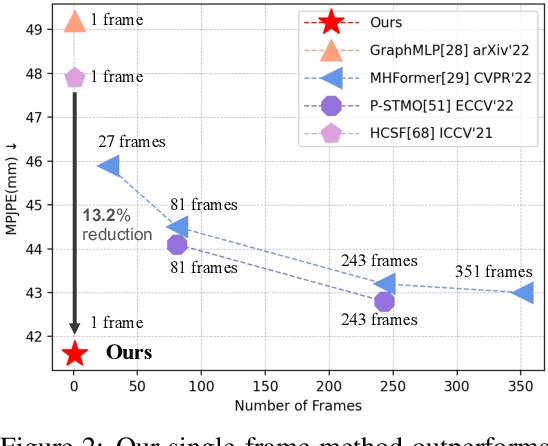
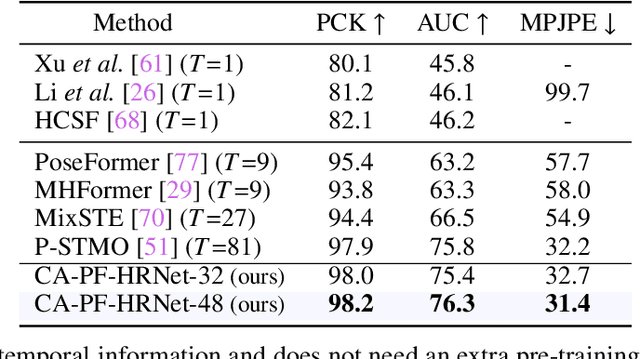
The dominant paradigm in 3D human pose estimation that lifts a 2D pose sequence to 3D heavily relies on long-term temporal clues (i.e., using a daunting number of video frames) for improved accuracy, which incurs performance saturation, intractable computation and the non-causal problem. This can be attributed to their inherent inability to perceive spatial context as plain 2D joint coordinates carry no visual cues. To address this issue, we propose a straightforward yet powerful solution: leveraging the readily available intermediate visual representations produced by off-the-shelf (pre-trained) 2D pose detectors -- no finetuning on the 3D task is even needed. The key observation is that, while the pose detector learns to localize 2D joints, such representations (e.g., feature maps) implicitly encode the joint-centric spatial context thanks to the regional operations in backbone networks. We design a simple baseline named Context-Aware PoseFormer to showcase its effectiveness. Without access to any temporal information, the proposed method significantly outperforms its context-agnostic counterpart, PoseFormer, and other state-of-the-art methods using up to hundreds of video frames regarding both speed and precision. Project page: https://qitaozhao.github.io/ContextAware-PoseFormer