 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA simple parameter-free and adaptive approach to optimization under a minimal local smoothness assumption
Paper and Code
Oct 01, 2018
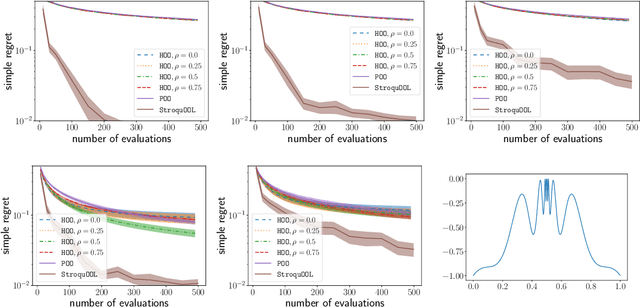
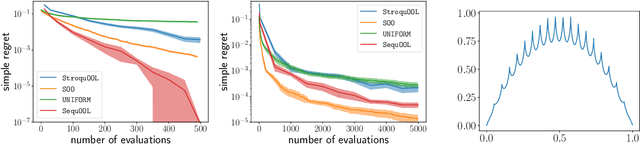

We study the problem of optimizing a function under a \emph{budgeted number of evaluations}. We only assume that the function is \emph{locally} smooth around one of its global optima. The difficulty of optimization is measured in terms of 1) the amount of \emph{noise} $b$ of the function evaluation and 2) the local smoothness, $d$, of the function. A smaller $d$ results in smaller optimization error. We come with a new, simple, and parameter-free approach. First, for all values of $b$ and $d$, this approach recovers at least the state-of-the-art regret guarantees. Second, our approach additionally obtains these results while being \textit{agnostic} to the values of both $b$ and $d$. This leads to the first algorithm that naturally adapts to an \textit{unknown} range of noise $b$ and leads to significant improvements in a moderate and low-noise regime. Third, our approach also obtains a remarkable improvement over the state-of-the-art \SOO algorithm when the noise is very low which includes the case of optimization under deterministic feedback ($b=0$). There, under our minimal local smoothness assumption, this improvement is of exponential magnitude and holds for a class of functions that covers the vast majority of functions that practitioners optimize ($d=0$). We show that our algorithmic improvement is also borne out in the numerical experiments, where we empirically show faster convergence on common benchmark functions.