Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Short Note on Analyzing Sequence Complexity in Trajectory Prediction Benchmarks
Paper and Code
Mar 27, 2020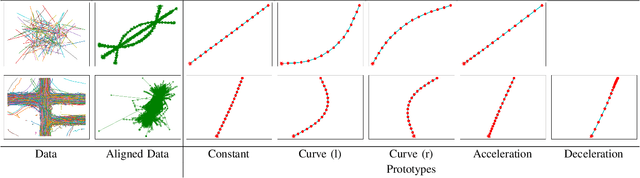
The analysis and quantification of sequence complexity is an open problem frequently encountered when defining trajectory prediction benchmarks. In order to enable a more informative assembly of a data basis, an approach for determining a dataset representation in terms of a small set of distinguishable prototypical sub-sequences is proposed. The approach employs a sequence alignment followed by a learning vector quantization (LVQ) stage. A first proof of concept on synthetically generated and real-world datasets shows the viability of the approach.
* Submitted to LHMP2020 Workshop
View paper on