 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Semantics-Assisted Video Captioning Model Trained with Scheduled Sampling
Paper and Code
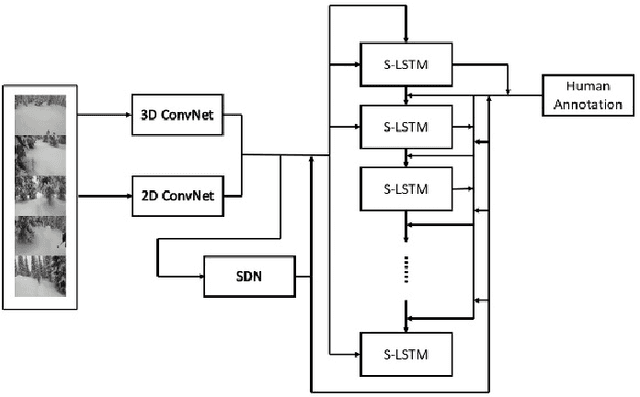
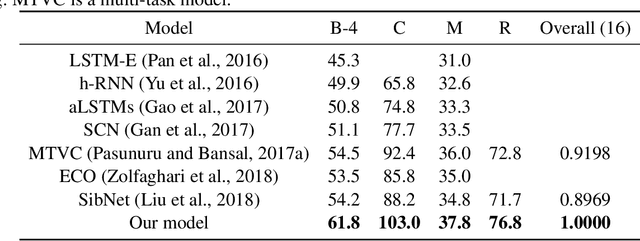
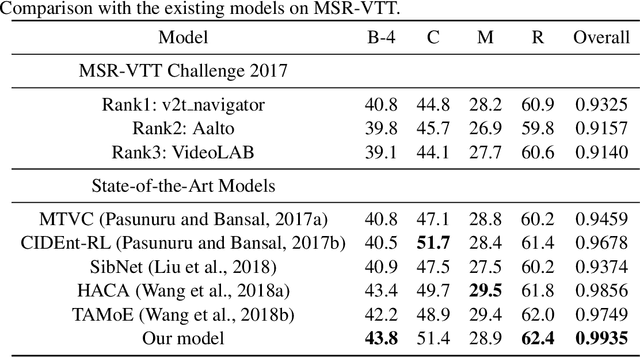
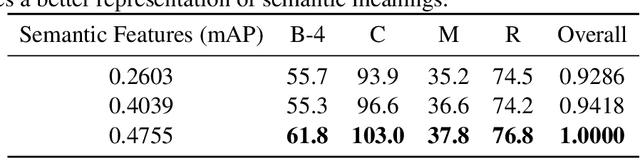
Given the features of a video, recurrent neural network can be used to automatically generate a caption for the video. Existing methods for video captioning have at least three limitations. First, semantic information has been widely applied to boost the performance of video captioning models, but existing networks often fail to provide meaningful semantic features. Second, Teacher Forcing algorithm is often utilized to optimize video captioning models, but during training and inference, different strategies are applied to guide word generation, which lead to poor performance. Third, current video captioning models are prone to generate relatively short captions, which express video contents inappropriately. Towards resolving these three problems, we make three improvements correspondingly. First of all, we utilize both static spatial features and dynamic spatio-temporal features as input for semantic detection network (SDN) in order to generate meaningful semantic features for videos. Then, we propose a scheduled sampling strategy which gradually transfers the training phase from a teacher guiding manner towards a more self teaching manner. At last, the ordinary logarithm probability loss function is leveraged by sentence length so that short sentence inclination is alleviated. Our model achieves state-of-the-art results on the Youtube2Text dataset and is competitive with the state-of-the-art models on the MSR-VTT dataset.