 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Review on the Applications of Transformer-based language models for Nucleotide Sequence Analysis
Paper and Code
Dec 10, 2024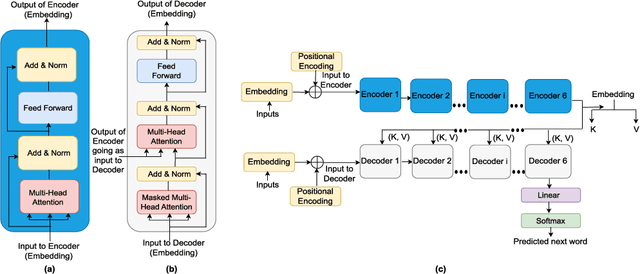

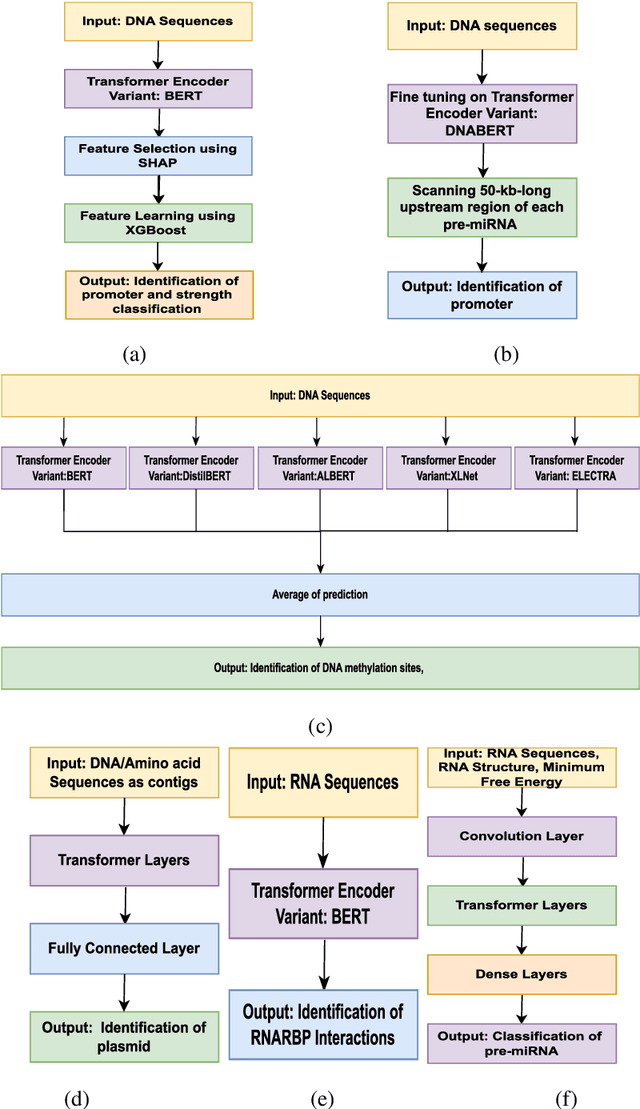
In recent times, Transformer-based language models are making quite an impact in the field of natural language processing. As relevant parallels can be drawn between biological sequences and natural languages, the models used in NLP can be easily extended and adapted for various applications in bioinformatics. In this regard, this paper introduces the major developments of Transformer-based models in the recent past in the context of nucleotide sequences. We have reviewed and analysed a large number of application-based papers on this subject, giving evidence of the main characterizing features and to different approaches that may be adopted to customize such powerful computational machines. We have also provided a structured description of the functioning of Transformers, that may enable even first time users to grab the essence of such complex architectures. We believe this review will help the scientific community in understanding the various applications of Transformer-based language models to nucleotide sequences. This work will motivate the readers to build on these methodologies to tackle also various other problems in the field of bioinformatics.