 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA ReLU Dense Layer to Improve the Performance of Neural Networks
Paper and Code
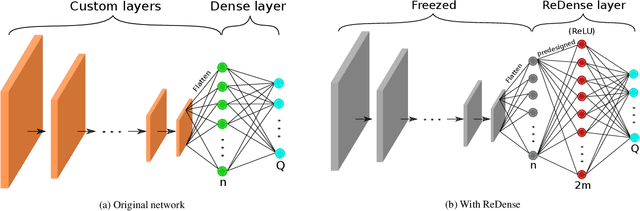
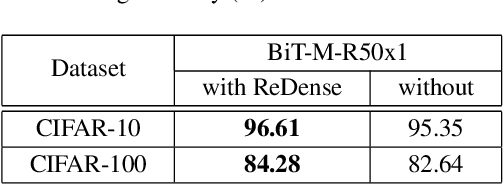
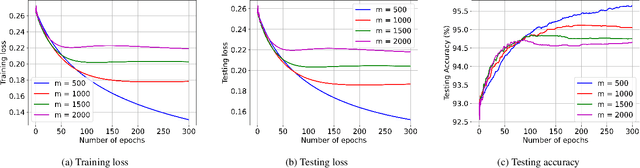
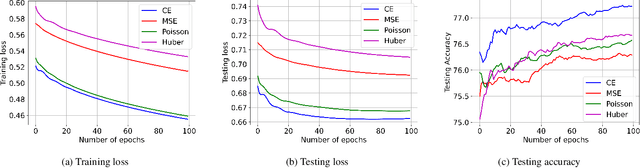
We propose ReDense as a simple and low complexity way to improve the performance of trained neural networks. We use a combination of random weights and rectified linear unit (ReLU) activation function to add a ReLU dense (ReDense) layer to the trained neural network such that it can achieve a lower training loss. The lossless flow property (LFP) of ReLU is the key to achieve the lower training loss while keeping the generalization error small. ReDense does not suffer from vanishing gradient problem in the training due to having a shallow structure. We experimentally show that ReDense can improve the training and testing performance of various neural network architectures with different optimization loss and activation functions. Finally, we test ReDense on some of the state-of-the-art architectures and show the performance improvement on benchmark datasets.