 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Provably-Efficient Model-Free Algorithm for Constrained Markov Decision Processes
Paper and Code
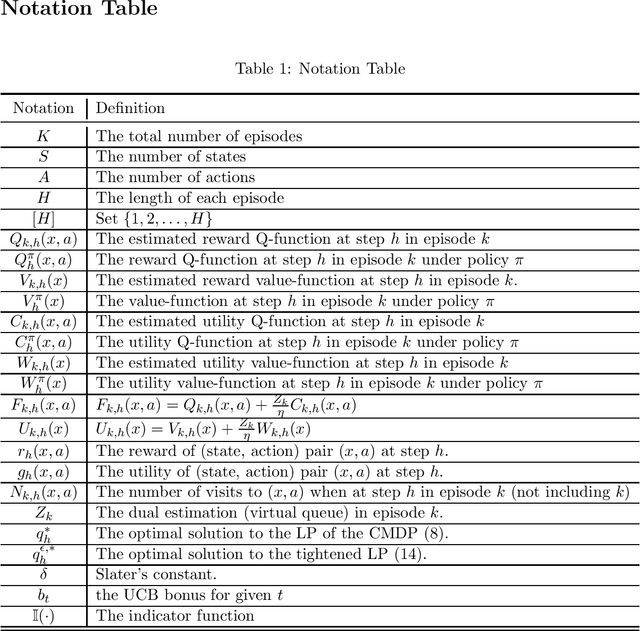
This paper presents the first {\em model-free}, {\em simulator-free} reinforcement learning algorithm for Constrained Markov Decision Processes (CMDPs) with sublinear regret and zero constraint violation. The algorithm is named Triple-Q because it has three key components: a Q-function (also called action-value function) for the cumulative reward, a Q-function for the cumulative utility for the constraint, and a virtual-Queue that (over)-estimates the cumulative constraint violation. Under Triple-Q, at each step, an action is chosen based on the pseudo-Q-value that is a combination of the three Q values. The algorithm updates the reward and utility Q-values with learning rates that depend on the visit counts to the corresponding (state, action) pairs and are periodically reset. In the episodic CMDP setting, Triple-Q achieves $\tilde{\cal O}\left(\frac{1 }{\delta}H^4 S^{\frac{1}{2}}A^{\frac{1}{2}}K^{\frac{4}{5}} \right)$ regret, where $K$ is the total number of episodes, $H$ is the number of steps in each episode, $S$ is the number of states, $A$ is the number of actions, and $\delta$ is Slater's constant. Furthermore, Triple-Q guarantees zero constraint violation when $K$ is sufficiently large. Finally, the computational complexity of Triple-Q is similar to SARSA for unconstrained MDPs and is computationally efficient.