Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Provable Defense for Deep Residual Networks
Paper and Code
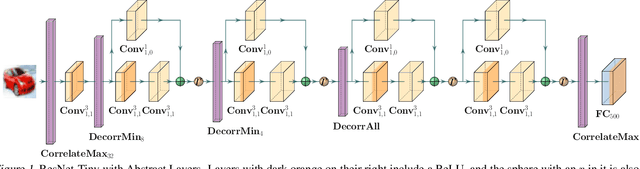



We present a training system, which can provably defend significantly larger neural networks than previously possible, including ResNet-34 and DenseNet-100. Our approach is based on differentiable abstract interpretation and introduces two novel concepts: (i) abstract layers for fine-tuning the precision and scalability of the abstraction, (ii) a flexible domain specific language (DSL) for describing training objectives that combine abstract and concrete losses with arbitrary specifications. Our training method is implemented in the DiffAI system.
View paper on