 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Novel Speech-Driven Lip-Sync Model with CNN and LSTM
Paper and Code
May 02, 2022

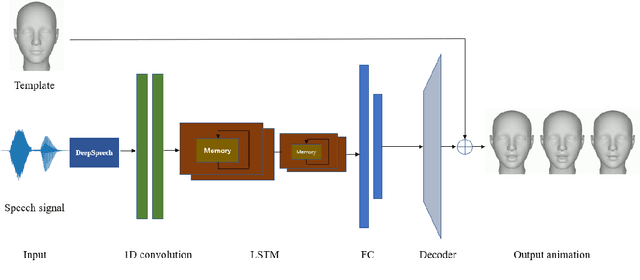
Generating synchronized and natural lip movement with speech is one of the most important tasks in creating realistic virtual characters. In this paper, we present a combined deep neural network of one-dimensional convolutions and LSTM to generate vertex displacement of a 3D template face model from variable-length speech input. The motion of the lower part of the face, which is represented by the vertex movement of 3D lip shapes, is consistent with the input speech. In order to enhance the robustness of the network to different sound signals, we adapt a trained speech recognition model to extract speech feature, and a velocity loss term is adopted to reduce the jitter of generated facial animation. We recorded a series of videos of a Chinese adult speaking Mandarin and created a new speech-animation dataset to compensate the lack of such public data. Qualitative and quantitative evaluations indicate that our model is able to generate smooth and natural lip movements synchronized with speech.