Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA New Geometric Approach to Latent Topic Modeling and Discovery
Paper and Code
Jan 05, 2013
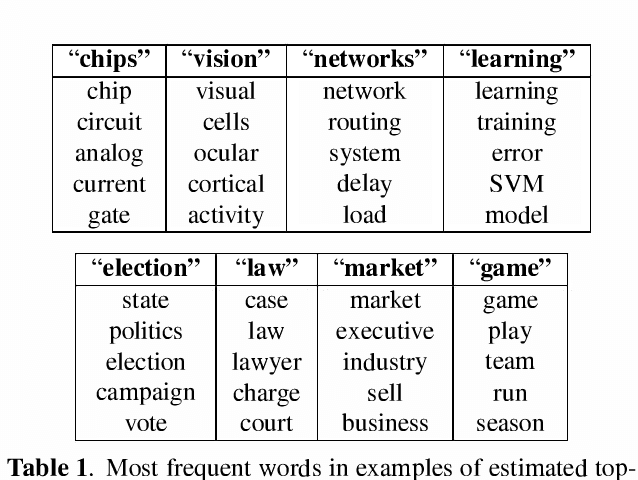
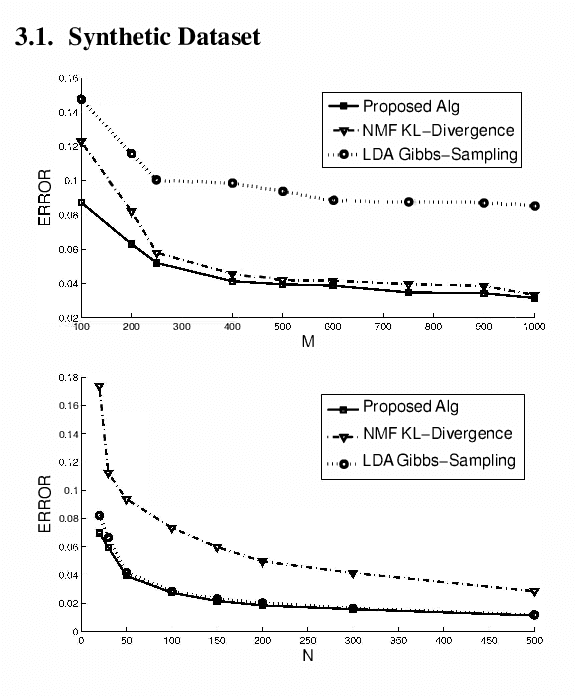

A new geometrically-motivated algorithm for nonnegative matrix factorization is developed and applied to the discovery of latent "topics" for text and image "document" corpora. The algorithm is based on robustly finding and clustering extreme points of empirical cross-document word-frequencies that correspond to novel "words" unique to each topic. In contrast to related approaches that are based on solving non-convex optimization problems using suboptimal approximations, locally-optimal methods, or heuristics, the new algorithm is convex, has polynomial complexity, and has competitive qualitative and quantitative performance compared to the current state-of-the-art approaches on synthetic and real-world datasets.
* This paper was submitted to the IEEE International Conference on
Acoustics, Speech and Signal Processing (ICASSP) 2013 on November 30, 2012
View paper on