 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Multi-Arm Bandit Approach To Subset Selection Under Constraints
Paper and Code
Feb 09, 2021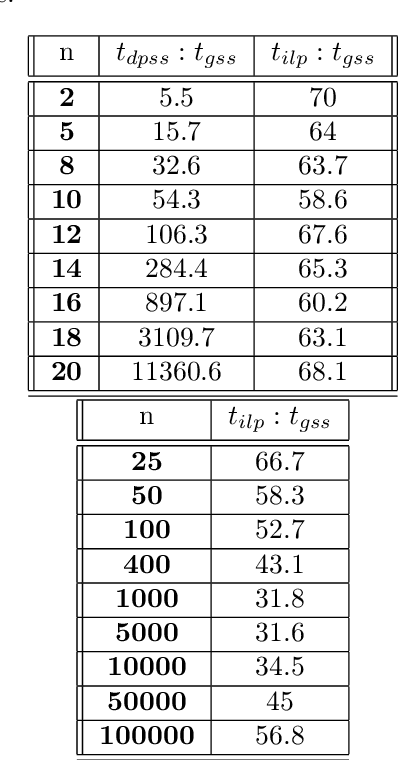
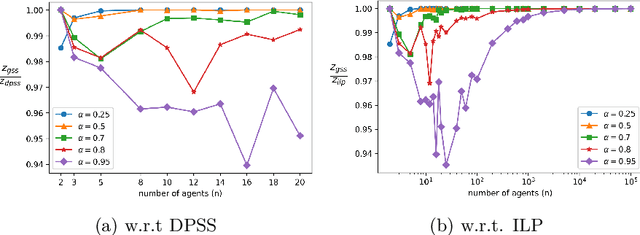
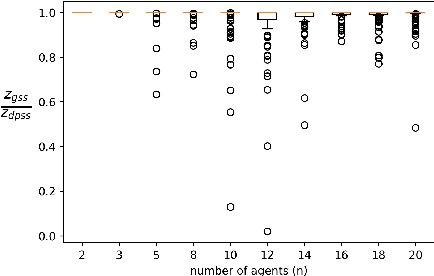
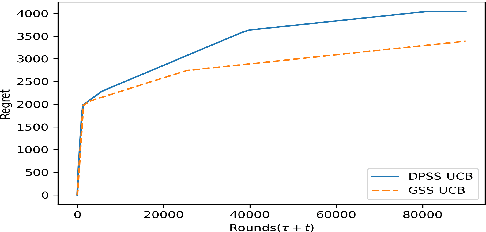
We explore the class of problems where a central planner needs to select a subset of agents, each with different quality and cost. The planner wants to maximize its utility while ensuring that the average quality of the selected agents is above a certain threshold. When the agents' quality is known, we formulate our problem as an integer linear program (ILP) and propose a deterministic algorithm, namely \dpss\ that provides an exact solution to our ILP. We then consider the setting when the qualities of the agents are unknown. We model this as a Multi-Arm Bandit (MAB) problem and propose \newalgo\ to learn the qualities over multiple rounds. We show that after a certain number of rounds, $\tau$, \newalgo\ outputs a subset of agents that satisfy the average quality constraint with a high probability. Next, we provide bounds on $\tau$ and prove that after $\tau$ rounds, the algorithm incurs a regret of $O(\ln T)$, where $T$ is the total number of rounds. We further illustrate the efficacy of \newalgo\ through simulations. To overcome the computational limitations of \dpss, we propose a polynomial-time greedy algorithm, namely \greedy, that provides an approximate solution to our ILP. We also compare the performance of \dpss\ and \greedy\ through experiments.