Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Memory Efficient Baseline for Open Domain Question Answering
Paper and Code
Dec 30, 2020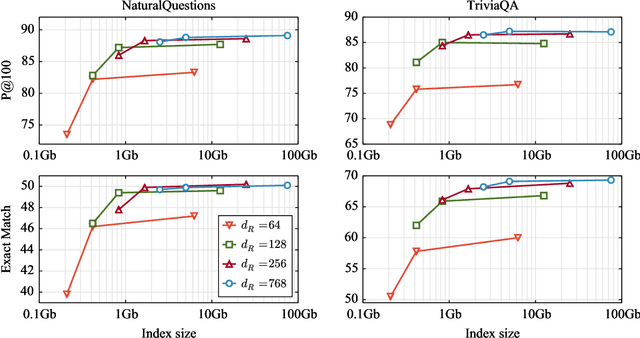
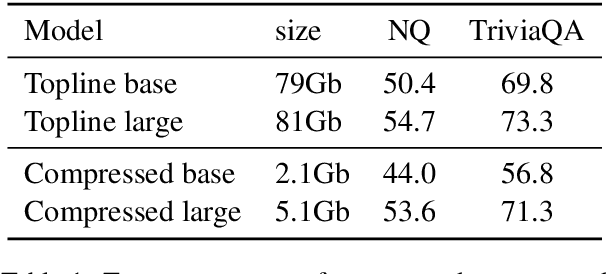
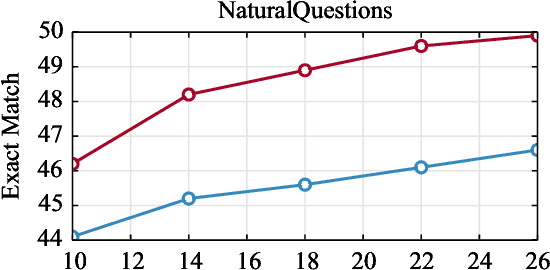
Recently, retrieval systems based on dense representations have led to important improvements in open-domain question answering, and related tasks. While very effective, this approach is also memory intensive, as the dense vectors for the whole knowledge source need to be kept in memory. In this paper, we study how the memory footprint of dense retriever-reader systems can be reduced. We consider three strategies to reduce the index size: dimension reduction, vector quantization and passage filtering. We evaluate our approach on two question answering benchmarks: TriviaQA and NaturalQuestions, showing that it is possible to get competitive systems using less than 6Gb of memory.
View paper on